YugabyteDB 快速指南
YugabyteDB 快速指南
在本文中,我们将探讨YugabyteDB。**YugabyteDB是一个为解决当今分布式云原生应用程序所面临困难而创建的SQL数据库。**Yugabyte DB为企业和开发人员提供了一个开源的高性能数据库。
2. YugabyteDB架构
**YugabyteDB是一个分布式SQL数据库。**更准确地说,它是一个关系型数据库,提供了一个逻辑上的单一数据库,部署在网络服务器集群中。
大多数关系型数据库的工作原理如下:
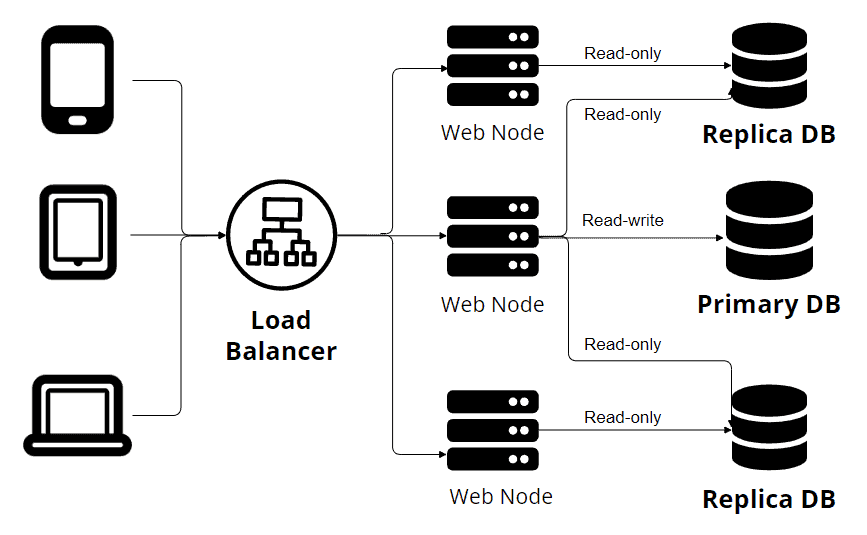
上面的图片代表了单一主复制。你可以看到在图片中,多个设备通过负载均衡器发出请求。此外,我们有多个Web节点连接到几个数据库节点。一个主节点向数据库写入数据,而其他副本只接受只读事务。这个原则运作良好。一个真实来源(一个主节点)允许我们避免数据冲突。但这并不是YugabyteDB的情况:
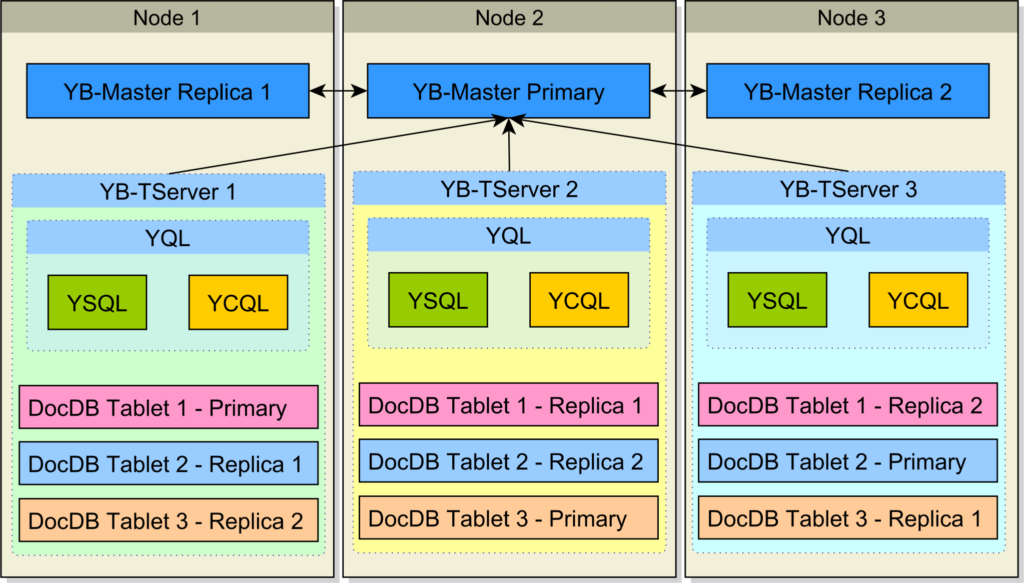
**与传统数据库复制系统不同,YugabyteDB利用分片来确保高可用性和容错性。**分片涉及将数据分布在集群的多个节点上,每个节点负责存储数据的一部分。通过将数据分割成更小的部分并将其分布到多个节点,YugabyteDB实现了并行性和负载均衡。如果一个节点失败,YugabyteDB的分片特性确保其余节点可以无缝接管服务数据的责任,保持不间断的可用性。
3. 数据库示例
3.1. Maven依赖
我们将从向我们的Maven项目添加以下依赖开始:
``<dependency>``
``<groupId>``org.postgresql``</groupId>``
``<artifactId>``postgresql``</artifactId>``
``</dependency>``
``<dependency>``
``<groupId>``org.springframework.boot``</groupId>``
``<artifactId>``spring-boot-starter-data-jpa``</artifactId>``
``</dependency>``
YugabyteDB与PostgreSQL兼容,因此我们可以轻松地使用PostgreSQL连接器作为我们的示例。
3.2. 数据库配置
根据我们的应用程序需求,有多种方式安装Yugabyte。但是,为了简单起见,我们将使用Docker镜像来启动我们的YugabyteDB实例。
我们将从本地拉取Docker镜像开始:
$ docker pull yugabytedb/yugabyte:latest
之后,我们可以启动我们的YugabyteDB实例:
$ docker run -d --name yugabyte -p7000:7000 -p9000:9000 -p5433:5433 yugabytedb/yugabyte:latest bin/yugabyted start --daemon=false
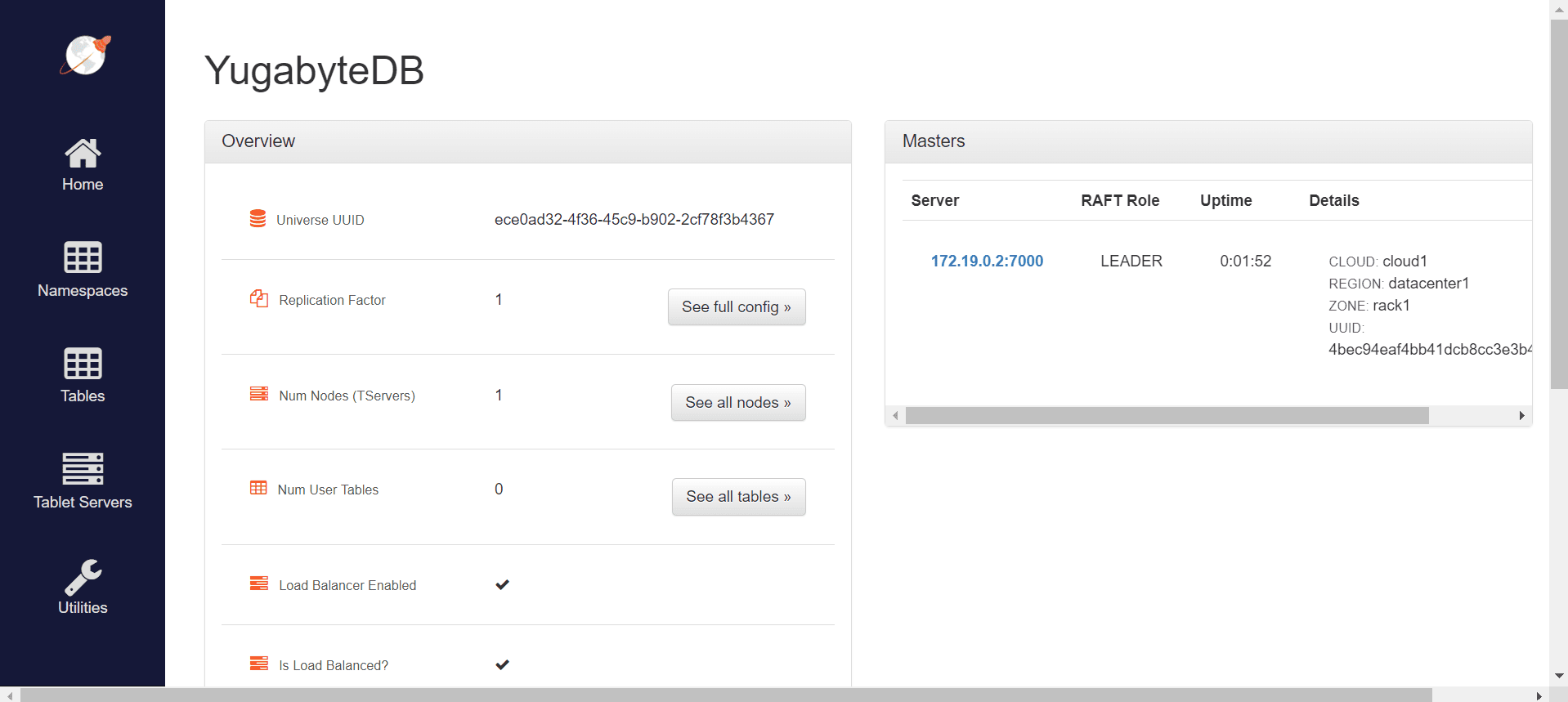
现在我们有一个全功能的YugabyteDB实例。我们可以通过访问_http://localhost:7000/_来查看管理员Web服务器UI:
现在我们可以开始在_application.properties_文件中配置数据库连接。
spring.datasource.url=jdbc:postgresql://localhost:5433/yugabyte
spring.datasource.username=yugabyte
spring.datasource.password=yugabyte
spring.jpa.hibernate.ddl-auto=create
spring.jpa.database-platform=org.hibernate.dialect.PostgreSQLDialect
我们可以看到配置是最小的,并且类似于PostgreSQL数据库的连接。我们还设置了_spring.jpa.hibernate.ddl-auto_属性值为_create_。这意味着Hibernate将负责创建与我们的实体匹配的表。我们坚持使用最少的配置。
3.3. 创建表
配置数据库后,我们可以开始创建实体。
@Entity
@Table(name = "users")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column
private String name;
// getters, setters, toString()
}
现在,我们可以运行我们的应用程序,并且用户表将自动创建。我们可以通过进入管理员UI并选择表格部分来检查它:
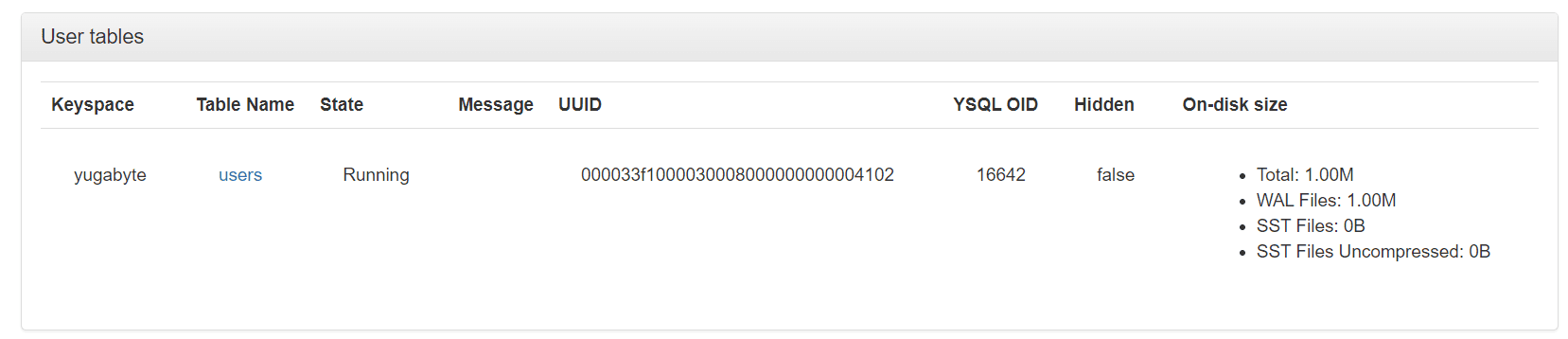
在这里我们可以看到创建了一个表。此外,我们还可以通过点击表名来获取有关表的更多信息。
我们还可以使用任何与PostgreSQL兼容的管理工具连接到我们的数据库,比如pgAdmin。
3.4. 读写数据
配置和创建表后,我们需要创建一个仓库—扩展现有的_JPARepository_接口:
public interface UserRepository extends JpaRepository`<User, Long>` {
}
JPARepository_是Spring Data JPA框架的一部分,它为我们提供了一组抽象和实用工具,以简化数据库访问。此外,它还带有诸如_save()、_findById()_和_delete()_等方法,允许我们快速简单地与数据库交互。
@Test
void givenTwoUsers_whenPersistUsingJPARepository_thenUserAreSaved() {
User user1 = new User();
user1.setName("Alex");
User user2 = new User();
user2.setName("John");
userRepository.save(user1);
userRepository.save(user2);
List`<User>` allUsers = userRepository.findAll();
assertEquals(2, allUsers.size());
}
上述示例展示了在数据库中进行两个简单的插入操作以及从表中检索所有数据的查询。为了简单起见,我们编写了一个测试来检查用户是否成功地保存在数据库中。
运行测试后,我们将得到测试通过的确认,这意味着我们成功地插入并查询了我们的用户。
3.5. 使用多个集群写数据
**这个数据库的一个优势是其高容错性和弹性。**我们在前面的示例中看到了一个简单的场景,但我们都知道我们通常需要运行数据库的多个实例。我们将在以下示例中看到YugabyteDB是如何管理的。
我们将从为我们的集群创建一个Docker网络开始:
$ docker network create yugabyte-network
之后,我们将创建我们的主要YugabyteDB节点:
$ docker run -d --name yugabyte1 --net=yugabyte-network -p7000:7000 -p9000:9000 -p5433:5433 yugabytedb/yugabyte:latest bin/yugabyted start --daemon=false
除此之外,我们可以添加两个更多的节点,这样我们就有一个三节点集群:
$ docker run -d --name yugabyte2 --net=yugabyte-network yugabytedb/yugabyte:latest bin/yugabyted start --join=yugabyte1 --daemon=false
$ docker run -d --name yugabyte3 --net=yugabyte-network yugabytedb/yugabyte:latest bin/yugabyted start --join=yugabyte1 --daemon=false
现在,如果我们打开在7000端口运行的管理员UI,我们可以看到副本因子是3。这意味着数据在所有三个数据库集群节点上共享。更准确地说,如果一个节点包含一个对象的主副本,其他两个节点将保留该对象的副本。
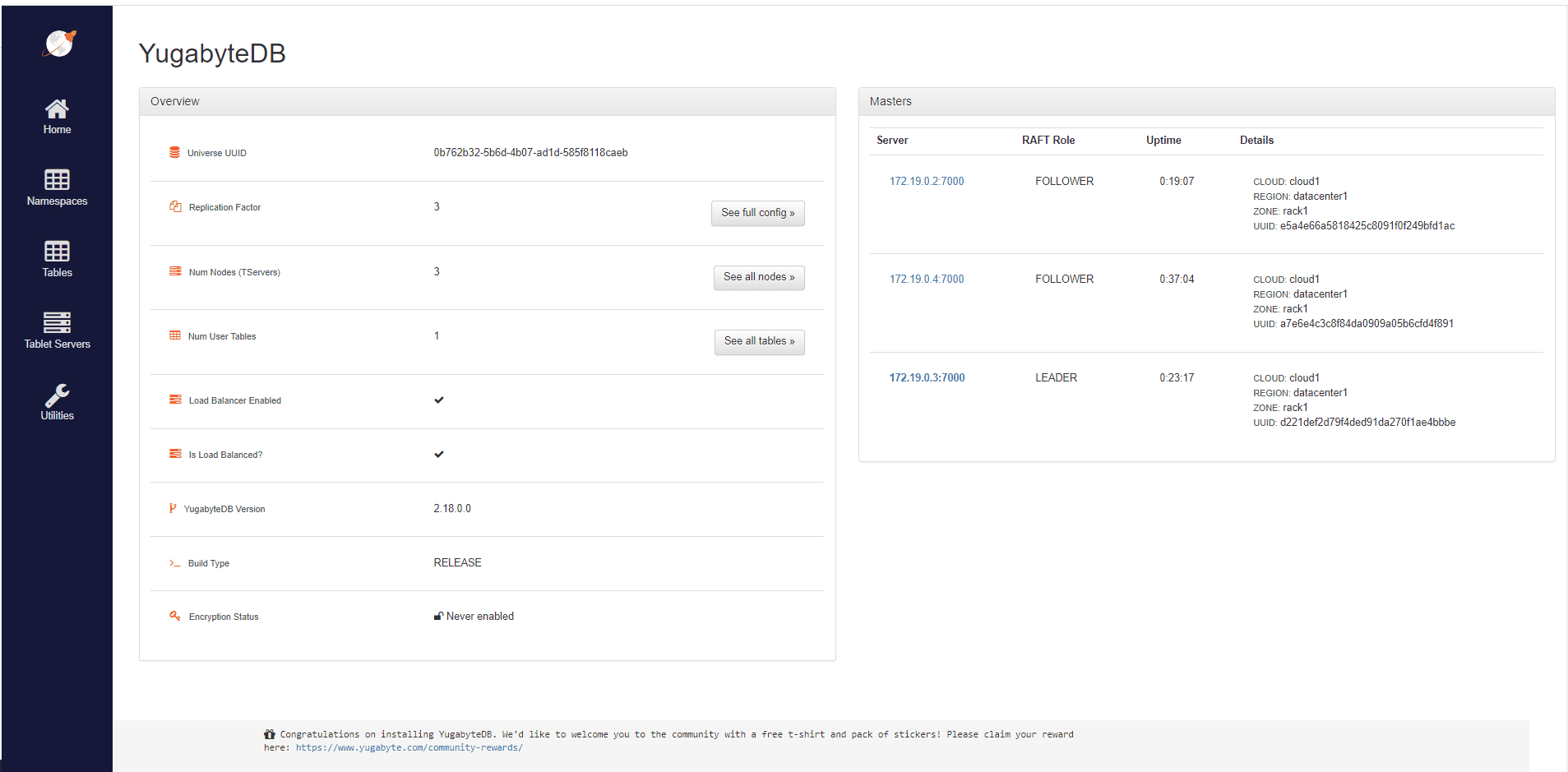
对于这个示例,我们将实现_CommandLineRunner_接口。通过覆盖_run(String…args)_方法,我们可以编写将在Spring应用程序上下文实例化后,在应用程序启动时调用的代码。
@Override
public void run(String... args) throws InterruptedException {
int iterationCount = 1_000;
int elementsPerIteration = 100;
for (int i = 0; i < iterationCount; i++) {
for (long j = 0; j < elementsPerIteration; j++) {
User user = new User();
userRepository.save(user);
}
Thread.sleep(1000);
}
}
通过这个脚本,我们将按顺序插入一系列元素批次,每批之间暂停一秒钟。我们希望观察数据库如何在节点之间分割负载。
首先,我们将运行脚本,进入管理员控制台并导航到_Tablet Servers_标签页。
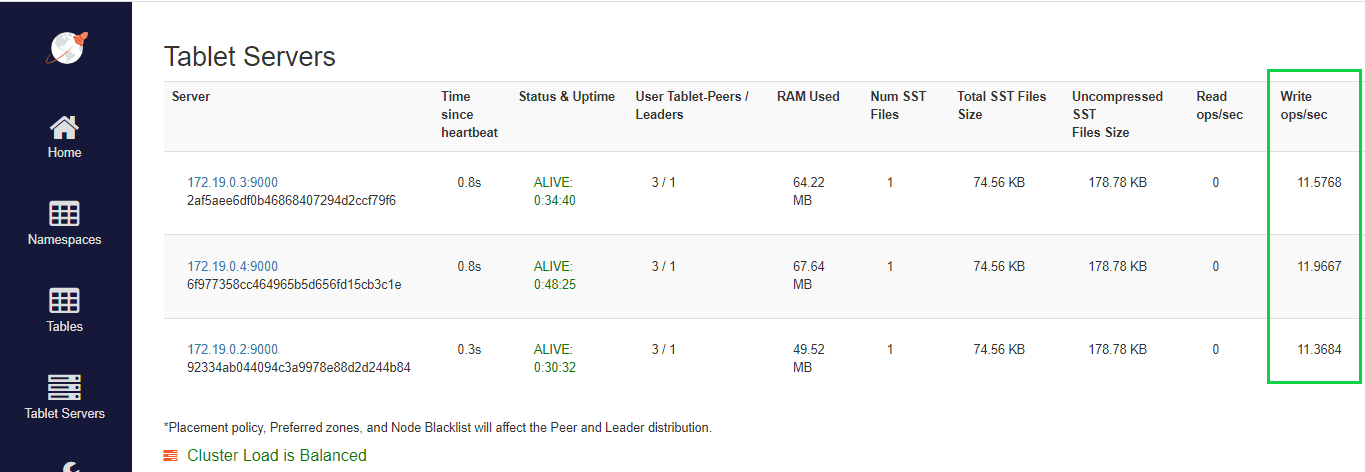
在这里我们可以看到,即使在最小的负载均衡配置下,YugabyteDB也可以在集群之间分割所有的负载。
3.6. 容错性
我们知道事情不可能总是完美的。因此,我们将模拟数据库集群的故障。现在,我们可以再次运行应用程序,但这次我们将在执行过程中停止一个集群:
$ docker stop yugabyte2
现在,如果我们稍等片刻并再次访问Tablet Servers页面,我们可以看到已停止的容器被标记为死亡。之后,所有的负载将在剩余的集群之间平衡。
这是通过YugabyteDB基于心跳的机制实现的。这个心跳机制涉及不同节点之间的定期通信,每个节点向其对等节点