Java中序列化Lambda表达式
Java中序列化Lambda表达式
1. 概述
通常来说,Java文档强烈不鼓励我们序列化一个lambda表达式。这是因为lambda表达式会生成合成结构。这些合成结构存在几个潜在问题:在源代码中没有对应的结构,不同Java编译器实现之间的变化,以及与不同JRE实现的兼容性问题。然而,有时序列化lambda是必要的。
在本教程中,我们将解释如何序列化lambda表达式及其背后的机制。
2. Lambda和序列化
当我们使用Java序列化来序列化或反序列化一个对象时,它的类和非静态字段都必须是可序列化的。否则,将导致_NotSerializableException_。同样地,在序列化lambda表达式时,我们必须确保其目标类型和捕获参数是可序列化的。
2.1. 一个失败的Lambda序列化示例
在源文件中,让我们使用_Runnable_接口来构建一个lambda表达式:
public class NotSerializableLambdaExpression {
public static Object getLambdaExpressionObject() {
Runnable r = () -> System.out.println("please serialize this message");
return r;
}
}
尝试序列化_Runnable_对象时,我们将得到一个_NotSerializableException_。在此之前,让我们稍微解释一下。
当JVM遇到一个lambda表达式时,它将使用内置的ASM来构建一个内部类。那么这个内部类看起来如何呢?我们可以通过在命令行上指定_jdk.internal.lambda.dumpProxyClasses_属性来转储这个生成的内部类:
-Djdk.internal.lambda.dumpProxyClasses=``<dump directory>``
注意这里:当我们用我们的目标目录替换_<dump directory>_时,这个目标目录最好是空的,因为我们的项目依赖于第三方库时,JVM可能会转储很多意想不到的生成的内部类。
转储后,我们可以使用适当的Java反编译器来检查这个生成的内部类:
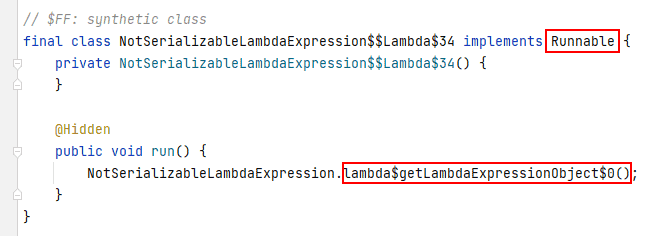
在上面的图片中,生成的内部类只实现了_Runnable_接口,这是lambda表达式的目标类型。此外,在_run_方法中,代码将调用_NotSerializableLambdaExpression.lambda$getLambdaExpressionObject$0_方法,这是由Java编译器生成的,表示我们的lambda表达式实现。
因为生成的内部类是我们lambda表达式的实际类,并且它没有实现_Serializable_接口,所以lambda表达式不适合序列化。
2.2. 如何序列化Lambda
此时,问题归结为:如何将_Serializable_接口添加到生成的内部类中?答案是将lambda表达式与一个结合了功能接口和_Serializable_接口的交叉类型进行强制转换。
例如,让我们将_Runnable_和_Serializable_组合成一个交叉类型:
Runnable r = (Runnable & Serializable) () -> System.out.println("please serialize this message");
现在,如果我们尝试序列化上述_Runnable_对象,它将成功。
然而,如果我们经常这样做,它可能会引入很多样板代码。为了使代码更清晰,我们可以定义一个新的接口,它同时实现了_Runnable_和_Serializable_:
interface SerializableRunnable extends Runnable, Serializable { }
然后我们可以使用它:
SerializableRunnable obj = () -> System.out.println("please serialize this message");
但是我们还应该小心不要捕获任何不可序列化的参数。例如,让我们定义另一个接口:
interface SerializableConsumer``<T>`` extends Consumer``<T>``, Serializable { }
然后我们可以选择_System.out::println_作为它的实现:
SerializableConsumer`<String>` obj = System.out::println;
结果,它将导致一个_NotSerializableException_。这是因为这个实现将捕获_System.out_变量作为其参数,其类是_PrintStream_,这不是可序列化的。
3. 背后的机制
此时,我们可能会想知道:在我们引入交叉类型后,下面发生了什么?
为了讨论的基础,让我们准备另一段代码:
public class SerializableLambdaExpression {
public static Object getLambdaExpressionObject() {
Runnable r = (Runnable & Serializable) () -> System.out.println("please serialize this message");
return r;
}
}
3.1. 编译后的类文件
编译后,我们可以使用_javap_来检查编译后的类:
javap -v -p SerializableLambdaExpression.class
-v_选项将打印详细消息,而-p_选项将显示私有方法。
我们可能会发现Java编译器提供了一个_$deserializeLambda$_方法,它接受一个_SerializedLambda_参数:

为了可读性,让我们将上述字节码反编译成Java代码:

上述_$deserializeLambda$方法的主要责任是构建一个对象。首先,它检查_SerializedLambda_的_getXXX_方法与lambda表达式的不同部分的详细信息。然后,如果所有条件都满足,它将调用_SerializableLambdaExpression::lambda$getLambdaExpressionObject$36ab28bd$1_方法引用来创建一个实例。否则,它将抛出一个_IllegalArgumentException。
3.2. 生成的内部类
除了检查编译后的类文件外,我们还需要检查新生成的内部类。所以,让我们使用_jdk.internal.lambda.dumpProxyClasses_属性来转储生成的内部类:
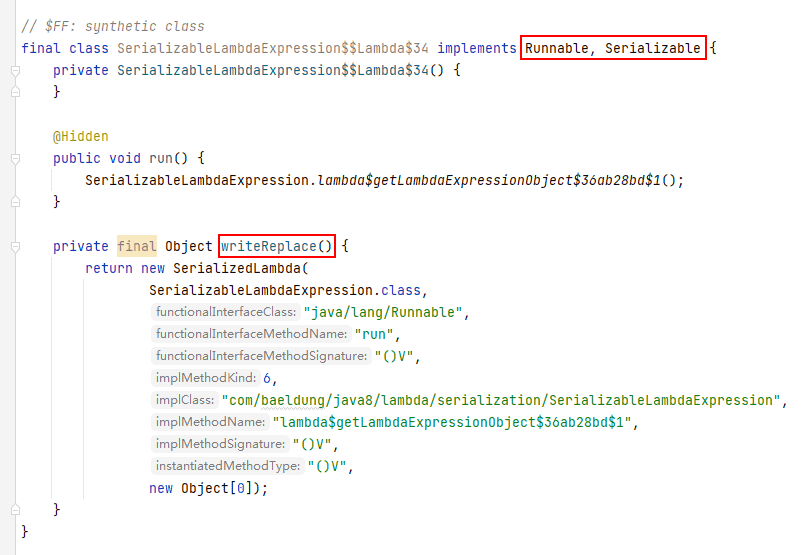
在上面的代码中,新生成的内部类实现了_Runnable_和_Serializable_接口,这意味着它适合序列化。而且,它还提供了一个额外的_writeReplace_方法。深入来看,这个方法返回了一个描述lambda表达式实现细节的_SerializedLambda_实例。
为了形成一个闭环,还缺少一件事:序列化的lambda文件。
3.3. 序列化的Lambda文件
由于序列化的lambda文件以二进制格式存储,我们可以使用十六进制工具来检查其内容:

在序列化流中,十六进制“AC ED”(Base64中的“rO0”)是流的魔术数字,十六进制“00 05”是流版本。但是,其余数据不是人类可读的。
根据对象序列化流协议,其余数据可以被解释:
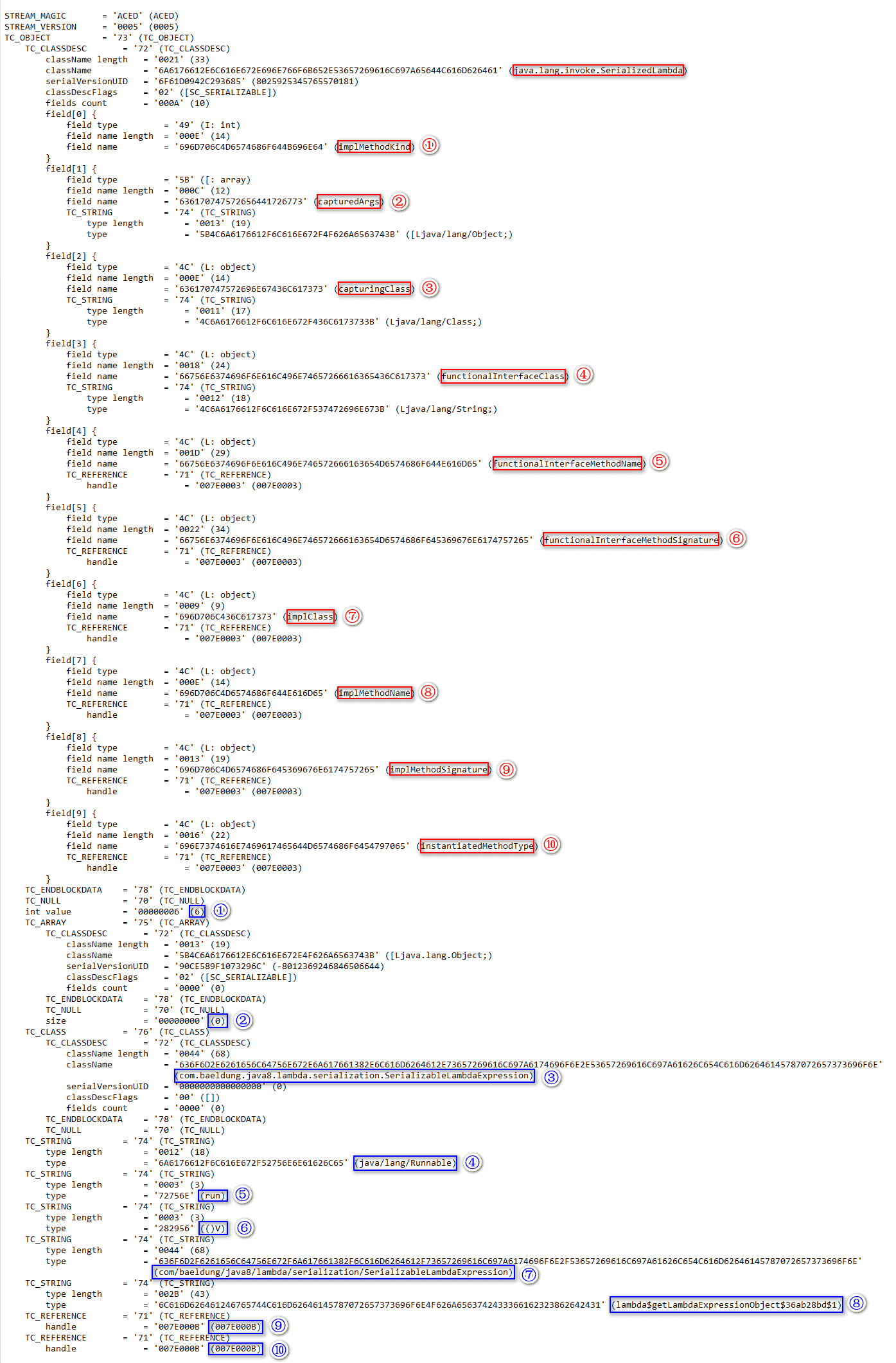
从上图中,我们可能会注意到序列化的lambda文件实际上包含了_SerializedLambda_类数据。具体来说,它包含了10个字段和相应的值。而且,这些_SerializedLambda_类的字段和值是在编译后的类文件中的_$deserializeLambda$_方法和生成的内部类中的_writeReplace_方法之间的桥梁。
3.4. 把所有部分结合起来
现在,是时候将不同的部分结合起来了:
当我们使用_ObjectOutputStream_来序列化一个lambda表达式时,_ObjectOutputStream_会发现生成的内部类包含一个返回_SerializedLambda_实例的_writeReplace_方法。然后,_ObjectOutputStream_将序列化这个_SerializedLambda_实例而不是原始对象。
接下来,当我们使用_ObjectInputStream_来反序列化序列化的lambda文件时,会创建一个_SerializedLambda_实例。然后,ObjectInputStream_将使用这个实例来调用_SerializedLambda_类中定义的_readResolve。而且,readResolve_方法将调用捕获类中定义的$deserializeLambda$_方法。最后,我们得到了反序列化的lambda表达式。
总之,_SerializedLambda_类是lambda序列化过程的关键。
4. 结论
在本文中,我们首先查看了一个失败的lambda序列化示例,并解释了为什么它会失败。然后,我们介绍了如何使lambda表达式可序列化。最后,我们探索了lambda序列化背后的机制。
像往常一样,本教程的源代码可以在GitHub上找到。