Apache Cassandra中的复制策略和分区
Apache Cassandra中的复制策略和分区
在本文中,我们将学习Apache Cassandra如何在集群中的节点之间分区和分配数据。此外,我们将看到Cassandra如何在多个节点中存储复制的数据以实现高可用性。
2. 节点
在Cassandra中,单个节点运行在服务器或虚拟机(VM)上。Cassandra是用Java语言编写的,这意味着Cassandra的运行实例是一个Java虚拟机(JVM)进程。Cassandra节点可以位于云中、本地数据中心或任何磁盘上。对于数据存储,根据推荐,我们应该使用本地存储或直连存储,而不是SAN。
Cassandra节点负责以分布式哈希表的形式存储所有数据。Cassandra提供了一个名为_nodetool_的工具,用于管理和检查节点或集群的状态。
3. 令牌环
Cassandra将集群中的每个节点映射到一个或多个连续环上的令牌。默认情况下,令牌是一个64位整数。因此,令牌的可能范围是从-263到263-1。它使用一致性哈希技术将节点映射到一个或多个令牌。
3.1. 每个节点的单个令牌
在每个节点一个令牌的情况下,每个节点负责一个令牌范围的值,该范围小于或等于分配给它的令牌,并且大于前一个节点分配的令牌。为了完成环,具有最低令牌值的第一个节点负责小于或等于其分配的令牌的值范围,并且大于具有最高令牌值的最后一个节点分配的令牌。
在数据写入时,Cassandra使用哈希函数根据分区键计算令牌值。这个令牌值与每个节点的令牌范围进行比较,以确定数据属于哪个节点。
让我们来看一个例子。下图显示了一个具有3个副本因子(RF)的8节点集群,并且每个节点分配了单个令牌:
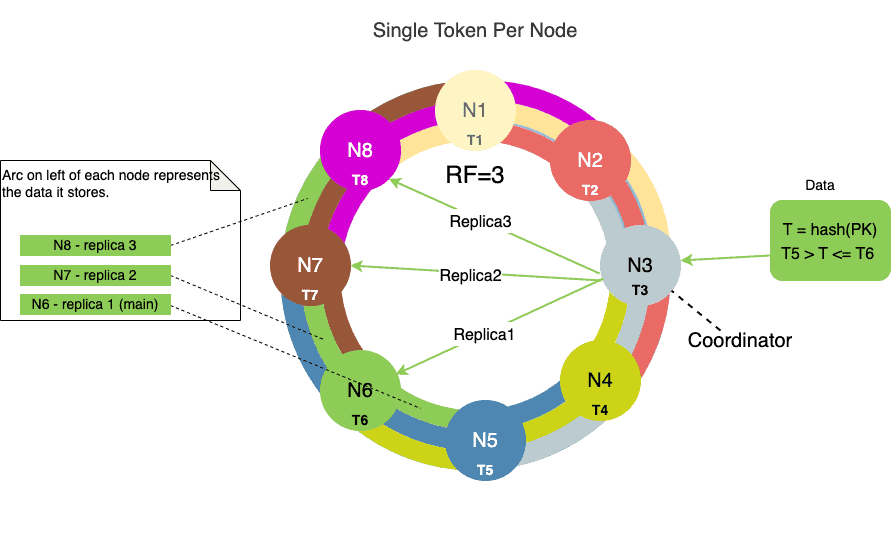
具有_RF=3_的集群意味着每个节点有3个副本。
上图中的内环表示主数据令牌范围。
每个节点一个令牌的缺点是在向集群添加或删除节点时创建的令牌不平衡。
假设,在N个节点的哈希环中,每个节点拥有相等数量的令牌,比如说100。进一步假设有一个现有节点X,它拥有100到200的令牌范围。现在,如果我们在节点X的左侧添加一个新节点Y,那么这个新节点Y现在拥有来自节点X的一半令牌。
也就是说,现在节点X将拥有100到150的令牌范围,节点Y将拥有151到200的令牌范围。一些来自节点X的数据必须移动到节点Y。这导致数据从节点X移动到另一个节点Y。
3.2. 每个节点的多个令牌(虚拟节点)
自Cassandra 2.0以来,默认启用了虚拟节点(vnodes)。在这种情况下,Cassandra将令牌范围拆分成较小的范围,并将这些较小范围的多个分配给集群中的每个节点。默认情况下,节点的令牌数量为256 - 这在_cassandra.yaml_文件中的_num_tokens_属性中设置 - 这意味着一个节点内有256个虚拟节点。
这种配置使得使用具有不同计算资源的机器维护Cassandra集群变得更加容易。这意味着我们可以通过将_num_tokens_属性设置为更大的值来为具有更多计算能力的机器分配更多的虚拟节点。另一方面,对于计算能力较小的机器,我们可以将_num_tokens_设置为较低的数字。
使用虚拟节点时,我们必须预先计算令牌值。否则,我们必须为每个节点预先计算令牌值,并将其设置为_num_tokens_属性的值。
下图显示了一个为每个节点分配了两个令牌的四节点集群:
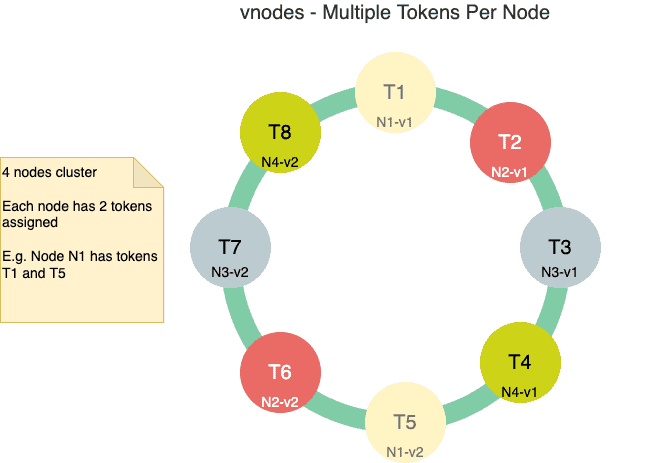
这种设置的优点是,当添加新节点或删除现有节点时,数据的重新分配会发生在/来自多个节点。
当我们在哈希环中添加一个新节点时,该节点现在将拥有多个令牌。这些令牌范围以前由多个节点拥有,因此添加后的数据移动是从多个节点进行的。
4. 分区器
分区器确定数据如何在Cassandra集群的节点之间分布。基本上,分区器是一个哈希函数,通过哈希分区键来确定令牌值。然后,这个分区键令牌用于确定和在环内分布行数据。
Cassandra提供了使用不同算法计算分区键哈希值的不同分区器。我们可以通过实现_IPartitioner_接口来提供和配置我们自己的分区器。
_Murmur3Partitioner_是自Cassandra版本1.2以来的默认分区器。它使用_MurmurHash_函数创建分区键的64位哈希。
在_Murmur3Partitioner_之前,Cassandra的默认分区器是_RandomPartitioner_。它使用_MD5_算法来哈希分区键。
两个分区器_Murmur3Partitioner_和_RandomPartitioner_都使用令牌来均匀地在环中分布数据。然而,两种分区器之间的主要区别是**_RandomPartitioner_使用加密哈希函数,而_Murmur3Partitioner_使用非加密哈希函数**。通常,加密哈希函数性能较差,耗时更长。
Cassandra通过在集群中的节点复制数据来实现高可用性和容错性。复制策略确定副本存储在集群中的位置。
集群中的每个节点不仅拥有分配的令牌范围内的数据,还拥有不同数据范围的副本。如果主节点宕机,那么这个副本节点可以响应对该数据范围的查询。
Cassandra在后台异步复制数据。复制因子(RF)是确定集群中有多少节点获得相同数据副本的数字。例如,环中的三个节点将具有_RF=3_的相同数据副本。我们已经在令牌环部分的图表中看到了数据复制。
Cassandra通过允许不同的__AbstractReplicationStrategy_类实现来提供可插拔的复制策略。开箱即用,Cassandra提供了几种实现,SimpleStrategy_和_NetworkTopologyStrategy。
一旦分区器计算出令牌并将数据放置在主节点中,_SimpleStrategy_就在环中的连续节点中放置副本。
另一方面,_NetworkTopologyStrategy_允许我们为每个数据中心指定不同的复制因子。在数据中心内,它将副本分配给不同机架上的节点,以最大化可用性。
_NetworkTopologyStrategy_是生产部署中键空间推荐使用的策略,无论是单个数据中心还是多个数据中心部署。
复制策略是为每个键空间独立定义的,并且在创建键空间时是必需的选项。
6. 一致性级别
一致性意味着我们在分布式系统中读取我们刚刚写入的相同数据。Cassandra在读写查询上提供了可调的一致性级别。换句话说,它为我们提供了可用性和一致性之间的细粒度权衡。
更高的一致性级别意味着需要更多的节点响应读写查询。这样,Cassandra更频繁地读取刚刚写入的相同数据。
对于读查询,一致性级别指定在返回数据给客户端之前需要多少副本响应。对于写查询,一致性级别指定在向客户端发送成功消息之前需要多少副本确认写入。
由于Cassandra是一个最终一致性的系统,_RF_确保写操作在后台异步地发生在剩余节点上。
7. Snitch
Snitch提供有关网络拓扑的信息,以便Cassandra可以有效地路由读写请求。Snitch确定哪个节点属于哪个数据中心和机架。它还确定集群中节点的相对主机接近度。
复制策略使用这些信息将副本放置在单个数据中心或多个数据中心内的适当节点中。
8. 结论
在本文中,我们学习了节点、环和令牌等基本概念。除此之外,我们学习了Cassandra如何在集群中的节点之间分区和复制数据。这些概念描述了Cassandra如何使用不同的策略高效地写入和读取数据。
这些是使Cassandra高度可扩展、可用、持久和可管理的几个架构组件。