Cassandra分区键、复合键和聚簇键 | Baeldung
Cassandra分区键、复合键和聚簇键 | Baeldung
1. 概述
在Cassandra NoSQL数据库中,数据分布和数据建模与传统的关系型数据库不同。
在本文中,我们将学习分区键、复合键和聚簇键如何构成主键。我们还将看到它们之间的差异。因此,我们将触及Cassandra中的数据分布架构和数据建模主题。
2. Apache Cassandra架构
Apache Cassandra是一个开源的NoSQL分布式数据库,旨在实现高可用性和线性可扩展性,而不影响性能。
这是Cassandra的高级架构图:
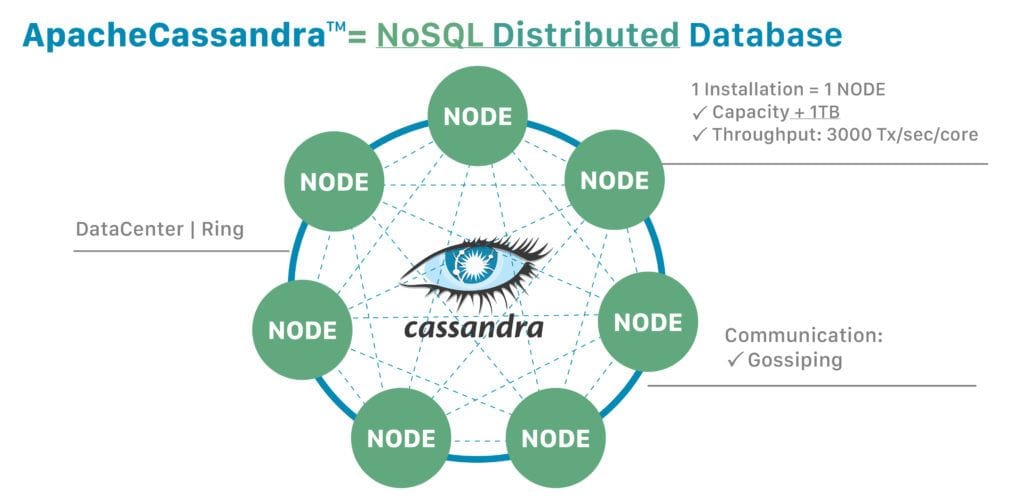
在Cassandra中,数据是跨集群分布的。此外,一个集群可能由在地理区域的数据中心安装的机架上的节点组成的环。
在更细粒度的层面上,称为_vnodes_的虚拟节点将数据所有权分配给物理机器。Vnodes通过使用一致性哈希技术来分配数据,使每个节点能够拥有多个小分区范围。
分区器是一个函数,它对分区键进行哈希以生成一个令牌。此令牌值表示一行,并用于标识它属于节点中的哪个分区范围。
然而,Cassandra客户端将集群视为统一的整体数据库,并使用Cassandra驱动库与之通信。
3. Cassandra数据建模
通常,数据建模是一个分析应用程序需求、识别实体及其关系、组织数据等的过程。在关系数据建模中,查询通常是整个数据建模过程中的事后考虑。
然而,在Cassandra中,数据访问查询驱动数据建模。反过来,查询是由应用程序工作流程驱动的。
此外,Cassandra数据模型中没有表连接,这意味着查询中的所有所需数据必须来自单个表。因此,表中的数据以非规范化格式存在。
接下来,在逻辑数据建模步骤中,我们通过定义键空间、表甚至表列来指定实际的数据库架构。然后,在物理数据建模步骤中,我们使用Cassandra查询语言(CQL)在集群中创建物理键空间 - 带有所有数据类型的表。
4. 主键
在Cassandra中,主键的工作方式是一个重要的概念。
Cassandra中的主键由一个或多个分区键和零个或多个聚簇键组件组成。这些组件的顺序总是将分区键放在第一位,然后是聚簇键。
除了使数据唯一之外,主键的分区键组件在数据放置中还扮演着额外的重要角色。因此,它提高了跨集群多个节点的数据读写性能。
现在,让我们看看主键的每个组件。
4.1. 分区键
分区键的主要目标是在集群中均匀分布数据并有效查询数据。
分区键用于数据放置,除了唯一标识数据外,并且始终是主键定义中的第一个值。
让我们通过一个例子来理解 - 一个包含应用程序日志的简单表,具有一个主键:
CREATE TABLE application_logs (
id INT,
app_name VARCHAR,
hostname VARCHAR,
log_datetime TIMESTAMP,
env VARCHAR,
log_level VARCHAR,
log_message TEXT,
PRIMARY KEY (app_name)
);
以下是上述表的一些示例数据:

正如我们之前学到的,Cassandra使用一致性哈希技术来生成分区键(app_name)的哈希值,并将行数据分配到节点内的分区范围。
让我们看看可能的数据存储:
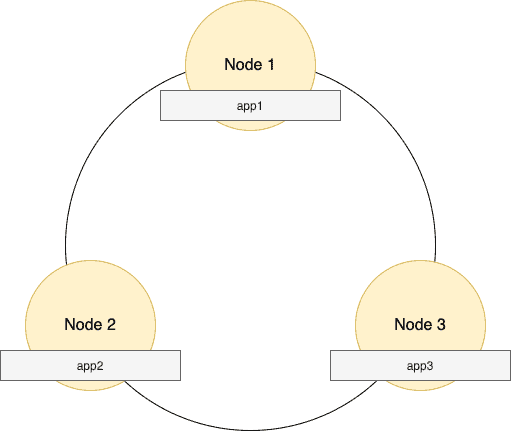
上述图表是一个可能的场景,其中_app1_、_app2_和_app3_的哈希值导致每一行分别存储在三个不同的节点 - Node1、Node2_和_Node3。
所有_app1_日志都发送到_Node1_,app2_日志发送到_Node2,app3_日志发送到_Node3。
没有在_where_子句中指定分区键的数据获取查询将导致低效的全集群扫描。
另一方面,在_where_子句中有分区键时,Cassandra使用一致性哈希技术来识别集群中确切的节点和节点内的确切分区范围。因此,获取数据查询是快速和高效的:
select * from application_logs where app_name = 'app1';
4.2. 复合分区键
如果我们需要组合多个列值以形成一个单一的分区键,我们使用复合分区键。
在这里,复合分区键的目标也是为了数据放置,除了唯一标识数据之外。因此,数据的存储和检索变得高效。
这里是一个将_app_name_和_env_列组合成复合分区键的表定义示例:
CREATE TABLE application_logs (
id INT,
app_name VARCHAR,
hostname VARCHAR,
log_datetime TIMESTAMP,
env VARCHAR,
log_level VARCHAR,
log_message TEXT,
PRIMARY KEY ((app_name, env))
);
上述定义中需要注意的重要事项是内括号围绕_app_name_和_env_主键定义。这个内括号指定_app_name_和_env_是分区键的一部分,而不是聚簇键。
如果我们去掉内括号并且只有单个括号,那么_app_name_就成为分区键,_env_成为聚簇键组件。
这里是上述表的一些示例数据:

让我们看看上述示例数据的可能数据分布。请注意:Cassandra为_app_name_和_env_列组合生成哈希值:
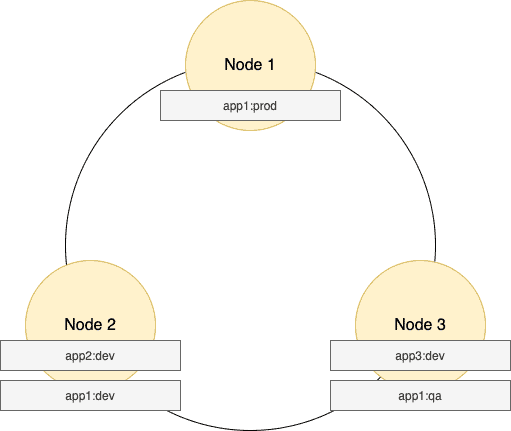
正如我们在上面看到的,可能的场景是_app1:prod, app1:dev, app1:qa_的哈希值导致这三行分别存储在三个不同的节点 - Node1、Node2_和_Node3。
所有来自_prod_环境的_app1_日志都发送到_Node1_,来自_dev_环境的_app1_日志发送到_Node2_,来自_qa_环境的_app1_日志发送到_Node3_。
最重要的是,为了有效地检索数据,获取查询中的_where_子句必须包含与主键定义中指定的相同顺序的所有复合分区键:
select * from application_logs where app_name = 'app1' and env = 'prod';
4.3. 聚簇键
正如我们上面提到的,分区是确定数据在节点内放置到哪个分区范围的过程。相比之下,聚簇是存储引擎的过程,用于在分区内对数据进行排序,基于定义为聚簇键的列。
此外,需要事先确定聚簇键列的选择 - 这是因为我们选择聚簇键列取决于我们希望在我们的应用程序中如何使用数据。
所有分区内的数据都存储在连续的存储中,按聚簇键列排序。因此,检索所需的排序数据非常高效。
让我们看一个包含复合分区键的聚簇键的示例表定义:
CREATE TABLE application_logs (
id INT,
app_name VARCHAR,
hostname VARCHAR,
log_datetime TIMESTAMP,
env VARCHAR,
log_level VARCHAR,
log_message TEXT,
PRIMARY KEY ((app_name, env), hostname, log_datetime)
);
让我们看看一些示例数据:

正如我们在上述表定义中看到的,我们已经将_hostname_和_log_datetime_作为聚簇键列。假设所有来自_app1_和_prod_环境的日志都存储在_Node1_中,Cassandra存储引擎将按_hostname_和_log_datetime_在分区内对这些日志进行字典排序。
默认情况下,Cassandra存储引擎按聚簇键列的升序排序数据,但我们可以通过在表定义中使用_WITH CLUSTERING ORDER BY_子句来控制聚簇列的排序顺序:
CREATE TABLE application_logs (
id INT,
app_name VARCHAR,
hostname VARCHAR,
log_datetime TIMESTAMP,
env VARCHAR,
log_level VARCHAR,
log_message TEXT,
PRIMARY KEY ((app_name,env), hostname, log_datetime)
)
WITH CLUSTERING ORDER BY (hostname ASC, log_datetime DESC);
根据上述定义,Cassandra存储引擎将在分区内按_hostname_的字典升序存储所有日志,但在每个_hostname_组内按_log_datetime_的降序存储。
现在,让我们看一个在_where_子句中包含聚簇列的数据获取查询的示例:
select * from application_logs
where
app_name = 'app1' and env = '