Apache Kafka中的自定义序列化器
Apache Kafka中的自定义序列化器
- 引言
在Apache Kafka中传输消息时,客户端和服务器约定使用一种共同的语法格式。Apache Kafka提供了默认的转换器(例如_String_和_Long_),但同时也支持特定用例的自定义序列化器。在本教程中,我们将看到如何实现它们。
序列化是将对象转换为字节的过程。反序列化是相反的过程——将字节流转换为对象。简而言之,它将内容转换为可读和可解释的信息。
正如我们所提到的,Apache Kafka为几种基本类型提供了预构建的序列化器和反序列化器,并允许我们实现自定义序列化器:
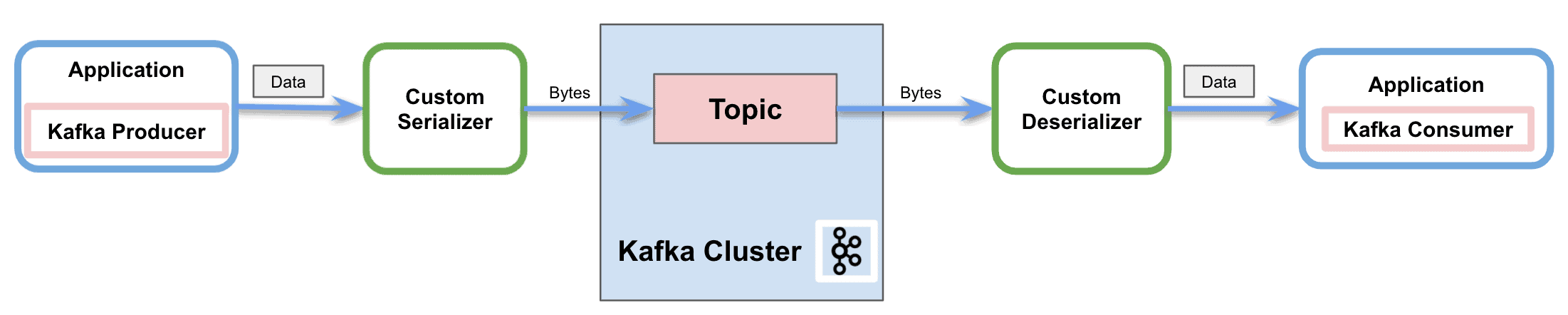
上图显示了通过网络向Kafka主题发送消息的过程。在此过程中,自定义序列化器在生产者发送消息到主题之前将对象转换为字节。同样,它还展示了反序列化器如何将字节转换回对象,以便消费者正确处理。
2.1. 自定义序列化器
Apache Kafka为几种基本类型提供了预构建的序列化器和反序列化器:
- StringSerializer
- ShortSerializer
- IntegerSerializer
- LongSerializer
- DoubleSerializer
- BytesSerializer
但它还提供了实现自定义(反)序列化器的能力。为了序列化我们自己的对象,我们将实现_Serializer_接口。同样,为了创建自定义反序列化器,我们将实现_Deserializer_接口。
两个接口都有三种方法可供覆盖:
- configure: 用于实现配置细节
- serialize/deserialize: 这些方法包括我们自定义序列化和反序列化的实际实现。
- close: 使用此方法关闭Kafka会话
3. 在Apache Kafka中实现自定义序列化器
Apache Kafka提供了自定义序列化器的能力。不仅可以为消息值实现特定的转换器,还可以为键实现。
3.1. 依赖性
为了实现示例,我们将简单地在_pom.xml_中添加Kafka Consumer API依赖项:
`<dependency>`
`<groupId>`org.apache.kafka`</groupId>`
`<artifactId>`kafka-clients`</artifactId>`
`<version>`3.4.0`</version>`
`</dependency>`
3.2. 自定义序列化器
首先,我们将使用Lombok指定通过Kafka发送的自定义对象:
@Data
@AllArgsConstructor
@NoArgsConstructor
@Builder
public class MessageDto {
private String message;
private String version;
}
接下来,我们将为生产者实现Kafka提供的_Serializer_接口以发送消息:
public class CustomSerializer implements Serializer```<MessageDto>``` {
private final ObjectMapper objectMapper = new ObjectMapper();
@Override
public void configure(Map``<String, ?>`` configs, boolean isKey) {
}
@Override
public byte[] serialize(String topic, MessageDto data) {
try {
if (data == null){
System.out.println("在序列化时收到Null");
return null;
}
System.out.println("序列化中...");
return objectMapper.writeValueAsBytes(data);
} catch (Exception e) {
throw new SerializationException("在将MessageDto序列化为byte[]时出错");
}
}
@Override
public void close() {
}
}
我们将覆盖接口的_serialize_方法。因此,在我们的实现中,我们将使用_Jackson ObjectMapper_转换自定义对象。然后我们将返回字节流以正确地将消息发送到网络。
3.3. 自定义反序列化器
同样,我们将为消费者实现_Deserializer_接口:
@Slf4j
public class CustomDeserializer implements Deserializer```<MessageDto>``` {
private ObjectMapper objectMapper = new ObjectMapper();
@Override
public void configure(Map``<String, ?>`` configs, boolean isKey) {
}
@Override
public MessageDto deserialize(String topic, byte[] data) {
try {
if (data == null){
System.out.println("在反序列化时收到Null");
return null;
}
System.out.println("反序列化中...");
return objectMapper.readValue(new String(data, "UTF-8"), MessageDto.class);
} catch (Exception e) {
throw new SerializationException("在将byte[]反序列化为MessageDto时出错");
}
}
@Override
public void close() {
}
}
正如前一节一样,我们将覆盖接口的_deserialize_方法。因此,我们将使用相同的_Jackson ObjectMapper_将字节流转换为自定义对象。
3.4. 消费示例消息
让我们通过一个工作示例来发送和接收带有自定义序列化器和反序列化器的示例消息。
首先,我们将创建并配置Kafka生产者:
private static KafkaProducer``````<String, MessageDto>`````` createKafkaProducer() {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, kafka.getBootstrapServers());
props.put(ProducerConfig.CLIENT_ID_CONFIG, CONSUMER_APP_ID);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "com.baeldung.kafka.serdes.CustomSerializer");
return new KafkaProducer<>(props);
}
我们将配置值序列化器属性为我们的自定义类,并将键序列化器配置为默认的_StringSerializer_。
其次,我们将创建Kafka消费者:
private static KafkaConsumer``````<String, MessageDto>`````` createKafkaConsumer() {
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafka.getBootstrapServers());
props.put(ConsumerConfig.CLIENT_ID_CONFIG, CONSUMER_APP_ID);
props.put(ConsumerConfig.GROUP_ID_CONFIG, CONSUMER_GROUP_ID);
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "com.baeldung.kafka.serdes.CustomDeserializer");
return new KafkaConsumer<>(props);
}
除了键和值反序列化器使用我们的自定义类,还必须包括组ID。除此之外,我们将自动偏移重置配置设置为_earliest_,以确保生产者在消费者开始之前发送了所有消息。
一旦我们创建了生产者和消费者客户端,就是时候发送一个示例消息了:
MessageDto msgProd = MessageDto.builder().message("test").version("1.0").build();
KafkaProducer``````<String, MessageDto>`````` producer = createKafkaProducer();
producer.send(new ProducerRecord``````<String, MessageDto>``````(TOPIC, "1", msgProd));
System.out.println("已发送消息 " + msgProd);
producer.close();
我们可以通过订阅主题来使用消费者接收消息:
AtomicReference```<MessageDto>``` msgCons = new AtomicReference<>();
KafkaConsumer``````<String, MessageDto>`````` consumer = createKafkaConsumer();
consumer.subscribe(Arrays.asList(TOPIC));
ConsumerRecords``````<String, MessageDto>`````` records = consumer.poll(Duration.ofSeconds(1));
records.forEach(record -> {
msgCons.set(record.value());
System.out.println("已接收消息 " + record.value());
});
consumer.close();
控制台中的结果是:
序列化中...
已发送消息 MessageDto(message=test, version=1.0)
反序列化中...
已接收消息 MessageDto(message=test, version=1.0)
4. 结论
在本教程中,我们展示了生产者如何在Apache Kafka中使用序列化器通过网络发送消息。同样,我们还展示了消费者如何使用反序列化器来解释接收到的消息。
此外,我们学习了可用的默认序列化器,最重要的是,实现了自定义序列化器和反序列化器的能力。
如常,代码可在GitHub上找到。 OK