Apache Kafka 教程
Apache Kafka 教程
1. 概览
在本教程中,我们将学习Kafka的基础知识——任何人都应该了解的用例和核心概念。之后,我们可以找到并理解关于Kafka的更详细文章。
2. Kafka 是什么?
Kafka是由Apache软件基金会开发的开源流处理平台。我们可以用它作为消息系统来解耦消息生产者和消费者,但与ActiveMQ等“传统”消息系统相比,它旨在处理实时数据流,并为数据的加工和存储提供分布式、容错和高度可扩展的架构。
因此,我们可以用它在各种用例中:
- 实时数据处理和分析
- 日志和事件数据聚合
- 监控和指标收集
- 点击流数据分析
- 欺诈检测
- 大数据管道中的流处理
3. 设置本地环境
如果我们第一次处理Kafka,可能希望有一个本地安装来体验它的功能。我们可以通过Docker的帮助快速实现。
3.1. 安装 Kafka
我们下载一个现有的镜像,并用以下命令运行一个容器实例:
docker run -p 9092:9092 -d bashj79/kafka-kraft
这将在主机系统的9092端口上使所谓的_Kafka代理_可用。现在,我们希望使用Kafka客户端连接到代理。我们可以使用多个客户端。
3.2. 使用 Kafka CLI
Kafka CLI是安装的一部分,并且在Docker容器内可用。我们可以通过连接到容器的bash来使用它。
首先,我们需要用以下命令找出容器的名称:
docker ps
在这个示例中,名称是_awesome_aryabhata_。然后我们使用以下命令连接到bash:
docker exec -it awesome_aryabhata /bin/bash
现在,我们可以创建一个主题(我们稍后将澄清这个术语)并列出所有现有主题:
cd /opt/kafka/bin
# 创建主题 'my-first-topic'
sh kafka-topics.sh --bootstrap-server localhost:9092 --create --topic my-first-topic --partitions 1 --replication-factor 1
# 列出主题
sh kafka-topics.sh --bootstrap-server localhost:9092 --list
# 向主题发送消息
sh kafka-console-producer.sh --bootstrap-server localhost:9092 --topic my-first-topic
> Hello World
> The weather is fine
> I love Kafka
3.3. 使用 Offset Explorer
Offset Explorer(前称:Kafka Tool)是一个用于管理Kafka的GUI应用程序。我们可以快速下载并安装它。然后,我们创建一个连接并指定Kafka代理的主机和端口:
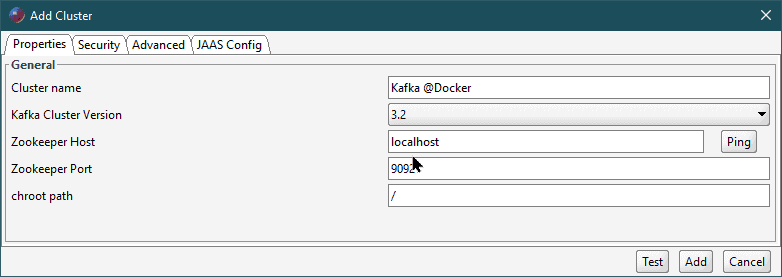
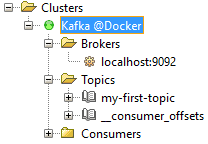
然后,我们可以探索架构:
3.4. 使用 Apache Kafka 的UI(Kafka UI)
Apache Kafka的UI(Kafka UI)是一个使用Spring Boot和React实现的Web UI,并以Docker容器的形式提供,可以通过以下命令简单安装:
docker run -it -p 8080:8080 -e DYNAMIC_CONFIG_ENABLED=true provectuslabs/kafka-ui
然后,我们可以在浏览器中使用http://localhost:8080打开UI并定义一个集群,如下所示:
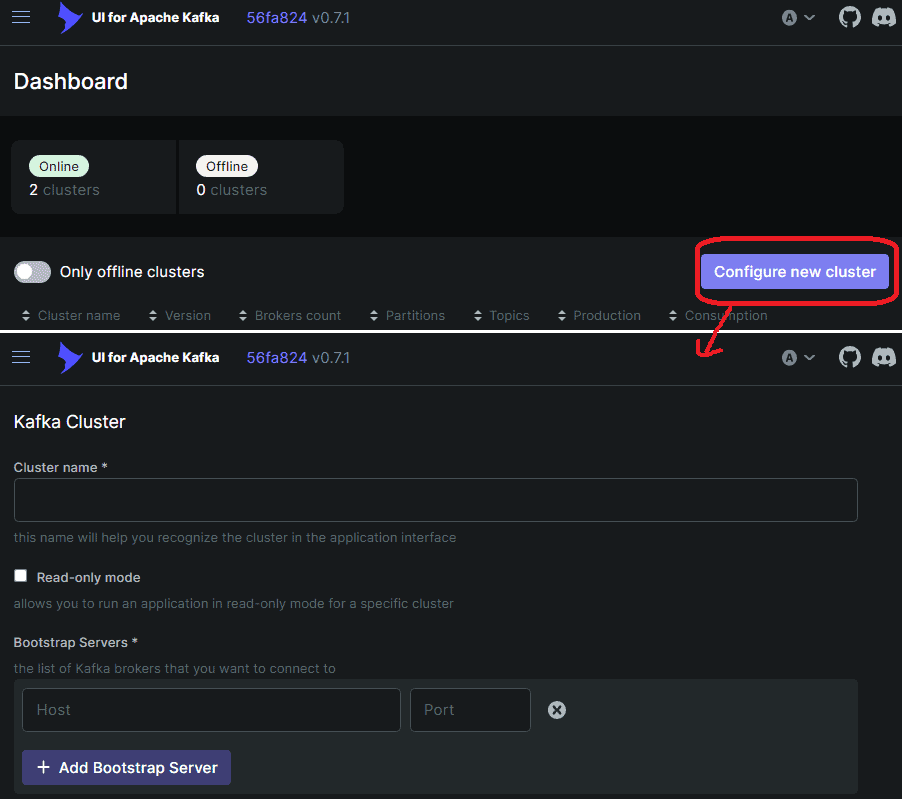
由于Kafka代理在与Kafka UI的后端不同的容器中运行,它将无法访问_localhost:9092_。我们可以改为使用_host.docker.internal:9092_来寻址主机系统,但这只是引导URL。
不幸的是,Kafka本身将返回一个响应,导致重定向到localhost:9092,这将不起作用。如果我们不想配置Kafka(因为这将与其他客户端冲突),我们需要从Kafka UI的容器端口9092到主机系统端口9092创建端口转发。下面的草图说明了连接:
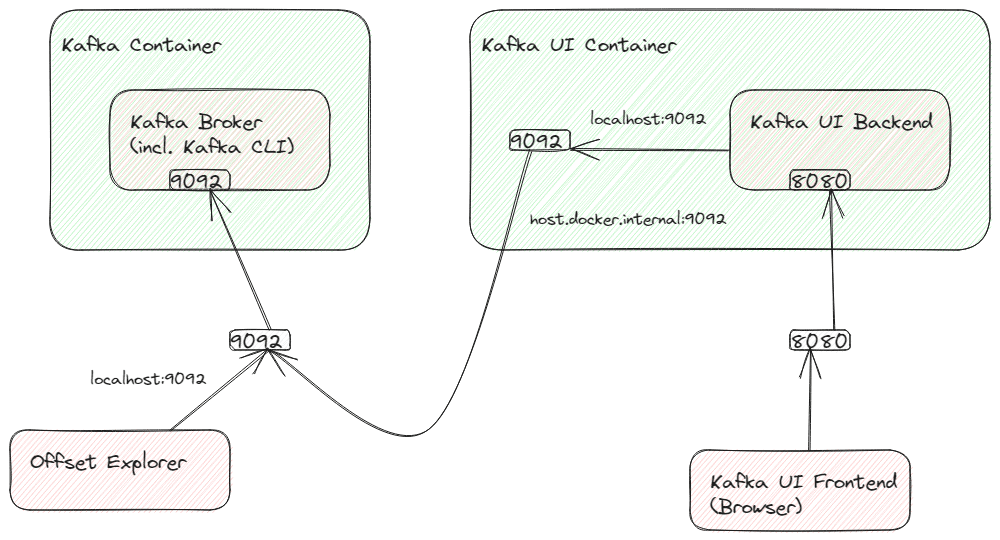
我们可以设置容器内部的端口转发,例如使用_socat_。我们需要在容器内(Alpine Linux)以root权限连接到容器的bash。所以我们需要这些命令,从主机系统的命令行开始:
# 连接到容器的bash(用'docker ps'找出名称)
docker exec -it --user=root `<name-of-kafka-ui-container>` /bin/sh
# 现在,我们已经连接到容器的bash。
# 让我们安装 'socat'
apk add socat
# 使用socat创建端口转发
socat tcp-listen:9092,fork tcp:host.docker.internal:9092
# 这将导致一个运行过程,只要容器在运行,我们就不杀死它
不幸的是,每次我们启动容器时都需要运行_socat_。另一种可能性是向Dockerfile提供扩展。
现在,我们可以在Kafka UI中将localhost:9092指定为引导服务器,并且应该能够查看和创建主题,如下所示:
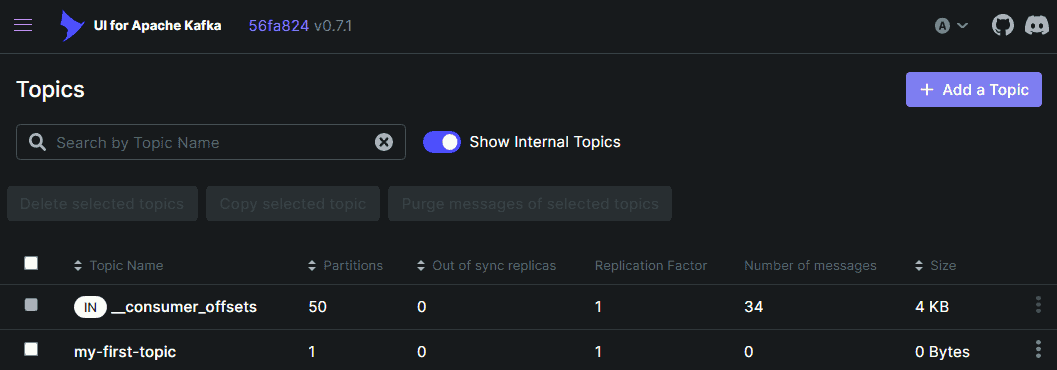
3.5. 使用 Kafka Java 客户端
我们必须向我们的项目添加以下Maven依赖项:
`<dependency>`
`<groupId>`org.apache.kafka`</groupId>`
`<artifactId>`kafka-clients`</artifactId>`
`<version>`3.5.1`</version>`
`</dependency>`
然后我们可以连接到Kafka并消费我们之前产生的消息:
// 指定连接属性
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "MyFirstConsumer");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// 接收消费者启动之前发送的消息
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// 使用props创建消费者。
try (final Consumer`<Long, String>` consumer = new KafkaConsumer<>(props)) {
// 订阅主题。
final String topic = "my-first-topic";
consumer.subscribe(Arrays.asList(topic));
// 从主题轮询消息并将其打印到控制台
consumer
.poll(Duration.ofMinutes(1))
.forEach(System.out::println);
}
当然,Kafka客户端在Spring中也有集成。
4. 基本概念
4.1. 生产者和消费者
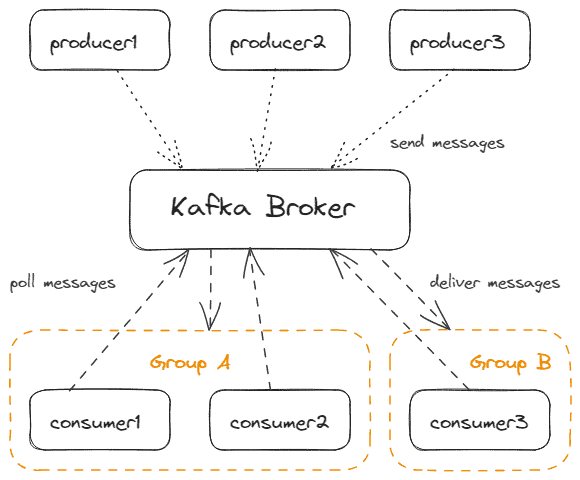
我们可以将Kafka客户端区分为消费者和生产者。 生产者向Kafka发送消息,而消费者从Kafka接收消息。它们通过积极地从Kafka轮询来接收消息。Kafka本身是被动的。这允许每个消费者拥有自己的性能而不阻塞Kafka。
当然,可以同时有多个生产者和多个消费者。而且,一个应用程序可以同时包含生产者和消费者。
消费者是_Kafka通过一个简单名称识别的消费者组_的一部分。只有一个消费者组的消费者会接收到消息。 这允许消费者扩展,并保证只有一次消息传递。
下图显示了多个生产者和消费者与Kafka一起工作:
4.2. 消息
消息(我们也可以称之为“记录”或“事件”,这取决于用例)是Kafka处理的基本数据单元。其有效载荷可以是任何二进制格式以及纯文本、Avro、XML或JSON等文本格式。
每个生产者都必须指定一个序列化器,将消息对象转换为二进制有效载荷格式。每个消费者都必须指定相应的反序列化器,将有效载荷格式转换回其JVM中的对象。我们简称这些组件为_SerDes_。有内置的SerDes,但我们也可以实现自定义SerDes。
下图显示了负载序列化和反序列化过程:
此外,消息还可以具有以下可选属性:
- 一个键,也可以是任何二进制格式。如果我们使用键,我们也需要SerDes。Kafka使用键进行分区(我们将在下一章中更详细地讨论)。
- 一个时间戳,指示消息何时产生。Kafka使用时间戳对消息进行排序或实现保留策略。
- 我们可以应用头来将元数据与有效载荷关联。例如,Spring默认为序列化和反序列化添加类型头。
4.3. 主题和分区
主题是生产者发布消息的逻辑通道或类别。 消费者订阅主题,以便在其消费者组的上下文中接收消息。
默认情况下,主题的保留策略是7天,即7天后,Kafka将自动删除消息,无论是否已交付给消费者。如果需要,我们可以配置此设置。
主题由分区(至少一个)组成。 确切地说,消息存储在主题的一个分区中。在一个分区内,消息会获得一个顺序号(偏移量)。这可以确保消息以存储在分区中的相同顺序传递给消费者。通过存储消费者组已经接收的偏移量,Kafka保证了只有一次交付。
通过处理多个分区,我们可以确定Kafka可以提供有序保证和在一组消费者进程上的负载平衡。
当消费者订阅主题时,一个消费者将被分配给一个分区,例如使用Java Kafka客户端API,正如我们已经看到的:
String topic = "my-first-topic";
consumer.subscribe(Arrays.asList(topic));
然而,对于消费者来说,选择它想要轮询消息的分区是可能的:
TopicPartition myPartition = new TopicPartition(topic, 1);
consumer.assign(Arrays.asList(myPartition));
这种变体的缺点是,所有组消费者都必须使用这个,所以自动将分区分配给组消费者将不会与连接到特定分区的单个消费者一起工作。此外,在架构更改(如向组中添加更多消费者)的情况下,重新平衡是不可能的。
理想情况下,我们有与分区一样多的消费者,这样每个消费者可以被精确地分配到一个分区,如下所示:
如果我们有比分区更多的消费者,那些消费者就不会从任何分区接收消息:
如果我们有比分区更少的消费者,消费者将从多个分区接收消息,这与最佳负载平衡冲突:
生产者不一定只向一个分区发送消息。 每个生产的消息自动分配给一个分区,遵循以下规则:
- 生产者可以作为消息的一部分指定一个分区。如果这样做了,这具有最高优先级
- 如果消息有一个键,分区是通过计算键的哈希来完成的。具有相同哈希的键将存储在同一个分区。理想情况下,我们至少有与分区一样多的哈希
- 否则,《粘性分区器》将消息分发到分区
再次,将消息存储到同一个分区将保留消息顺序,而将消息存储到不同的分区将导致无序但并行处理。
如果我们的默认分区不符合我们的期望,我们可以简单地实现自定义分区器。因此,我们实现Partitioner接口,并在生产者的初始化期间注册它:
Properties producerProperties = new Properties();
// ...
producerProperties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, MyCustomPartitioner.class.getName());
KafkaProducer`<String, String>` producer = new KafkaProducer<> (producerProperties);
下图显示了生产者和消费者及其与分区的连接:
每个生产者都有自己的分区器,所以如果我们想确保消息在主题内一致地分区,我们必须确保所有生产者的分区器以相同的方式工作,或者我们应该只使用单个生产者。
分区在Kafka代理处按它们到达的顺序存储消息。通常,生产者不会将每条消息作为单个请求发送,但它会将多个消息在批处理中发送。如果我们需要确保消息的顺序和在一个分区内的只有一次交付,我们需要事务感知的生产者和消费者。
4.4. 集群和分区副本
正如我们所发现的,Kafka使用主题分区来允许并行消息传递和消费者负载平衡。但Kafka本身必须是可扩展和容错的。所以我们通常不使用单个Kafka代理,而是多个代理的_集群_。 这些代理的行为并不完全相同,但每个代理都被分配了特殊任务,如果一个代理失败,集群的其他部分可以吸收这些任务。
为了理解这一点,我们需要扩展我们对主题的理解。在创建主题时,我们不仅指定了分区的数量,还指定了使用同步管理分区的代理数量。我们称这为_副本因子_。例如,使用Kafka CLI,我们可以创建一个有6个分区的主题,每个分区在3个代理上同步:
sh kafka-topics.sh --bootstrap-server localhost:9092 --create --topic my-replicated-topic --partitions 6 --replication-factor 3
例如,三个副本因子意味着集群可以承受多达两个副本故障(N-1容错)。我们必须确保我们至少有我们指定为副本因子的代理数量。 否则,Kafka不会在代理数量增加之前创建主题。
为了更好的效率,分区的副本仅在一个方向上发生。 Kafka通过宣布其中一个代理为_分区领导者_来实现这一点。生产者只向分区领导者发送消息,然后领导者与其它代理同步。消费者也会从分区领导者那里轮询,因为增加的消费者组的偏移量也需要同步。
分区领导权分散在多个代理上。 Kafka尝试为不同的分区找到不同的代理。让我们看一个有四个代理和两个分区,副本因子为三的例子:
代理1是分区1的领导者,代理4是分区2的领导者。所以每个客户端在发送或轮询这些分区的消息时将连接到这些代理。要获取有关分区领导者和其他可用代理(元数据)的信息,有一个特殊的引导机制。总之,我们可以说每个代理都可以提供集群的元数据,所以客户端可以与这些代理中的每一个初始化连接,然后重定向到分区领导者。这就是为什么我们可以指定多个代理作为引导服务器。
如果一个分区领导代理失败,Kafka将宣布一个仍在工作的代理为新的分区领导者。然后,所有客户端都必须连接到新的领导者。在我们的示例中,如果代理1失败,代理2成为分区1的新领导者。然后,之前连接到代理1的客户端必须切换到代理2。
Kafka使用Kraft(在早期版本中:Zookeeper)对集群内的所有代理进行编排。
4.4. 将所有内容整合在一起
如果我们将生产者和消费者与一个由三个代理组成的集群结合在一起,管理一个有三分区和副本因子为3的单一主题,我们将得到这样的架构:
5. 生态系统
我们已经知道,有多个客户端如CLI、基于Java的客户端与Spring应用程序集成,以及多个GUI工具可用于连接Kafka。当然,还有其他编程语言的更多客户端API(例如C/C++、Python或Javascript),但它们不是Kafka项目的一部分。
在这些API的基础上,还有用于特殊目的的进一步API。
5.1. Kafka Connect API
Kafka Connect是一个与第三方系统交换数据的API。有现有的连接器,例如用于AWS S3、JDBC或甚至用于在不同的Kafka集群之间交换数据的连接器。当然,我们也可以编写自定义连接器。
5.2. Kafka Streams API
Kafka Streams是一个用于实现流处理应用程序的API,该应用程序从Kafka主题获取输入,并将结果存储在另一个Kafka主题中。
5.3. KSQL
KSQL是建立在Kafka Streams之上的类似SQL的接口。它不需要我们开发Java代码,但我们可以使用类似SQL的语法来定义与Kafka交换消息的流处理。为此,我们使用ksqlDB,它连接到Kafka集群。我们可以使用CLI或Java客户端应用程序访问ksqlDB。
5.4. Kafka REST代理
Kafka REST代理提供了一个Kafka集群的RESTful接口。这样,我们就不需要任何Kafka客户端,并避免使用原生的Kafka协议。它允许Web前端连接到Kafka,并使得使用网络组件如API网关或防火墙成为可能。
5.5. Kafka Operators for Kubernetes (Strimzi)
Strimzi是一个开源项目,提供了一种在Kubernetes和OpenShift平台上运行Kafka的方式。它引入了自定义的Kubernetes资源,使得以Kubernetes原生方式声明和管理Kafka相关资源变得更加容易。它遵循Operator模式,即操作员自动化任务,如Kafka集群的配置、扩展、滚动更新和监控。
6. 结论
在本文中,我们了解到Kafka旨在实现高可扩展性和容错性。生产者收集消息并以批次发送,主题被划分为分区以允许并行消息传递和消费者负载平衡,复制在多个代理上完成以确保容错性。
像往常一样,所有的代码实现都可以在GitHub上找到。
OK