Apache Cassandra中的二级索引
Apache Cassandra中的二级索引
在本教程中,我们将讨论如何在Apache Cassandra中使用二级索引。
我们将看到数据库中数据是如何分布的,并探索所有索引类型。最后,我们将讨论使用二级索引的最佳实践和建议。
2.1. 主键
主键是数据建模中最重要的选择,它唯一地标识了一个数据记录。它至少由一个分区键和零个或多个聚簇列组成。
分区键定义了我们如何在集群中分割数据。聚簇列在磁盘上对数据进行排序,以实现快速的读取操作。
让我们看一个例子:
CREATE TABLE company (
company_name text,
employee_name text,
employee_email text,
employee_age int,
PRIMARY KEY ((company_name), employee_email)
);
这里,我们定义了_company_name_作为用于在节点之间均匀分布表数据的分区键。接下来,由于我们指定了_employee_email_作为聚簇列,Cassandra使用它在每个节点上按升序保持数据,以便有效检索行。
2.2. 集群拓扑
Cassandra提供了与可用节点数量成正比的线性可扩展性和性能。
节点被放置在一个环中,形成一个数据中心,通过连接多个地理分布的数据中心,我们创建了一个集群。
Cassandra自动分割数据,无需手动干预,从而使其准备好处理大数据。
接下来,让我们看看Cassandra如何通过_company_name_对表进行分区:
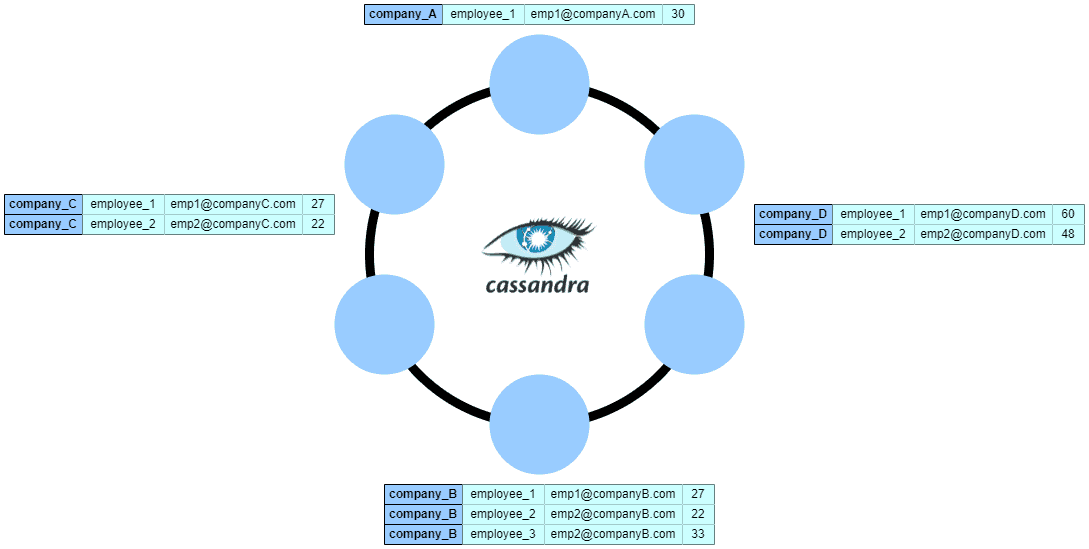
正如我们所看到的,_company_表使用分区键_company_name_进行分割,并跨节点分布。我们可以注意到Cassandra将具有相同_company_name_值的行分组,并将其存储在磁盘上的同一物理分区上。因此,我们可以以最小的I/O成本读取给定公司的所有数据。
此外,我们可以通过定义复制因子在数据中心跨数据中心复制数据。复制因子N将在集群中的N个不同节点上存储每行数据。
我们可以在数据中心级别而不是集群级别指定副本的数量。因此,我们可以拥有一个由多个数据中心组成的集群,每个数据中心具有不同的复制因子。
3. 在非主键上查询
让我们以我们之前定义的_company_表为例,尝试通过_employee_age_进行搜索:
SELECT * FROM company WHERE employee_age = 30;
InvalidRequest: Error from server: code=2200 [Invalid query] message="Cannot execute this query as it might involve data filtering and thus may have unpredictable performance. If you want to execute this query despite the performance unpredictability, use ALLOW FILTERING"
我们收到此错误消息是因为我们不能查询不是主键一部分的列,除非我们使用_ALLOW FILTERING_子句。
然而,即使我们技术上可以,我们也不应在生产中使用它,因为_ALLOW FILTERING_是昂贵且耗时的。这是因为,在后台,它开始对集群中的所有节点进行全面的表扫描以获取结果,这会对性能产生负面影响。
然而,一个可接受的使用案例是我们在单个分区上需要进行大量过滤。在这种情况下,Cassandra仍然执行表扫描,但我们可以将其限制在单个节点:
SELECT * FROM company WHERE company_name = 'company_a' AND employee_age = 30 ALLOW FILTERING;
因为我们将_company_name_聚簇列作为条件添加,Cassandra使用它来识别保存所有公司数据的节点。因此,它只对个特定节点上的表数据执行表扫描。
Cassandra中的二级索引解决了对非主键列进行查询的需求。
当我们插入数据时,Cassandra使用一个名为_commitlog_的仅追加文件来存储更改,因此写入速度很快。同时,数据被写入到一个名为_Memtable_的键/列值的内存缓存中。定期地,Cassandra将_Memtable_刷新到磁盘上,形成不可变的_SSTable_。
接下来,让我们看看Cassandra中的三种不同的索引方法,并讨论它们的优缺点。
4.1. 常规二级索引(2i)
常规二级索引是我们为在非主键列上执行查询可以定义的最基本索引。
让我们在_employee_age_列上定义一个二级索引:
CREATE INDEX IF NOT EXISTS ON company (employee_age);
有了这个,我们现在可以无误地通过_employee_age_运行查询:
SELECT * FROM company WHERE employee_age = 30;
company_name | employee_email | employee_age | employee_name
--------------+-------------------+--------------+---------------
company_A | emp1@companyA.com | 30 | employee_1
当我们设置索引时,Cassandra在后台创建了一个隐藏表来存储索引数据:
CREATE TABLE company_by_employee_age_idx (
employee_age int,
company_name text,
employee_email text,
PRIMARY KEY ((employee_age), company_name, employee_email)
);
与常规表不同,Cassandra不使用集群范围内的分区器来分发隐藏索引表。索引数据与源数据在同一节点上共存。
因此,当使用二级索引执行搜索查询时,Cassandra从每个节点读取索引数据并收集所有结果。如果我们的集群有很多节点,这可能导致数据传输增加和高延迟。
我们可能会问自己为什么Cassandra不根据主键将索引表分区到节点上。答案是将索引数据与源数据一起存储可以减少延迟。另外,由于索引更新是在本地执行的,而不是通过网络,因此没有因连接问题而丢失更新操作的风险。此外,如果索引列数据分布不均匀,Cassandra避免了创建宽分区。
当我们向附加了二级索引的表中插入数据时,Cassandra同时写入索引和基础_Memtable_。此外,两者同时被刷新到_SSTable_ s。因此,索引数据将具有与源数据不同的生命周期。
当我们根据二级索引读取数据时,Cassandra首先检索所有匹配行的主键,然后使用它们从源表中获取所有数据。
4.2. SSTable附加二级索引(SASI)
SASI引入了将_SSTable_生命周期绑定到索引的新概念。执行内存索引,然后与_SSTable_一起将索引刷新到磁盘,减少了磁盘使用并节省了CPU周期。
让我们看看如何定义SASI索引:
CREATE CUSTOM INDEX IF NOT EXISTS company_by_employee_age ON company (employee_age) USING 'org.apache.cassandra.index.sasi.SASIIndex';
SASI的优点是标记化文本搜索、快速范围扫描和内存索引。另一方面,一个缺点是它生成大索引文件,特别是启用文本标记化时。
最后,我们应该注意,在DataStax Enterprise(DSE)中,SASI索引是实验性的。DataStax不支持SASI索引用于生产。
4.3. 存储附加索引(SAI)
存储附加索引是DataStax Astra和DataStax Enterprise数据库中可用的高度可扩展的数据索引机制。我们可以在任何列上定义一个或多个SAI索引,然后使用范围查询(仅限数字)、_CONTAIN_语义和过滤查询。
SAI为每个列存储单独的索引文件,并包含指向_SSTable_中源数据偏移量的指针。一旦我们将数据插入到索引列中,它首先会被写入到内存中。每当Cassandra将数据从内存刷新到磁盘时,它会将索引与数据表一起写入。
**这种方法通过减少写入开销,将吞吐量提高了43%,将延迟提高了230%。**与SASI和2i相比,它用于索引的磁盘空间显著减少,故障点更少,并具有更简化的架构。
让我们使用SAI定义我们的索引:
CREATE CUSTOM INDEX ON company (employee_age) USING 'StorageAttachedIndex' WITH OPTIONS = {'case_sensitive': false, 'normalize': false};
规范化选项将特殊字符转换为其基本字符。例如,我们可以将德语字符_ö_规范化为常规的o,从而在不输入特殊字符的情况下实现查询匹配。因此,例如,我们可以通过简单地使用“schon”作为条件来搜索术语“schön”。
4.4. 最佳实践
首先,当我们在查询中使用二级索引时,建议添加分区键作为条件。结果,我们可以将读取操作减少到单个节点(加上根据一致性级别而定的副本):
SELECT * FROM company WHERE employee_age = 30 AND company_name = "company_A";
其次,我们可以将查询限制在一系列分区键上,并限制参与获取结果的节点数量:
SELECT * FROM company WHERE employee_age = 30 AND company_name IN ("company_A", "company_B", "company_C");
第三,如果我们只需要结果的一个子集,我们可以向查询添加限制。这也减少了参与读取路径的节点数量:
SELECT * FROM company WHERE employee_age = 30 LIMIT 10;
此外,我们必须避免在具有非常低基数的列上定义二级索引(性别、真/假列等),因为它们产生非常宽的分区,影响性能。
同样,具有高基数的列 (社会安全号码、电子邮件等)将导致索引具有非常细粒度的分区,在最坏的情况下,将迫使集群协调器访问所有主副本。
最后,我们必须避免在频繁更新的列上使用二级索引。其背后的原因是Cassandra使用不可变数据结构,频繁更新会增加磁盘上的写操作次数。
5. 结论
在本文中,我们探讨了Cassandra如何在数据中心中分割数据,并探讨了三种类型的二级索引。
在考虑二级索引之前,我们应该考虑将我们的数据反规范化到第二个表中,并保持它与主表的更新,如果我们计划频繁访问它。
另一方面,如果数据访问是零星的,添加一个单独的表会增加不必要的复杂性。因此,引入二级索引是更好的选择。毫无疑问,存储附加索引是我们所拥有的三种索引选项中的最佳选择,提供了最佳的性能和简化的架构。
![]()
![]()


OK