RabbitMQ中的通道和连接 | Baeldung
RabbitMQ中的通道和连接 | Baeldung
1. 引言
在本快速教程中,我们将展示如何使用与RabbitMQ相关的API,涉及两个核心概念:连接和通道。
2. RabbitMQ快速回顾
RabbitMQ是AMQP(高级消息队列协议)的流行实现,被各种规模的公司广泛用于处理其消息需求。
从应用程序的角度来看,我们通常关心AMQP的主要实体:虚拟主机、交换机和队列。由于我们已在早期文章中涵盖了这些概念,这里,我们将专注于两个较少讨论的概念的细节:连接和通道。
客户端与RabbitMQ代理交互的第一步是建立连接。AMPQ是一个应用层协议,因此这种连接是在传输层协议之上发生的。这可以是常规的TCP连接或使用TLS加密的连接。连接的主要作用是提供一个安全的通道,通过这个通道客户端可以与代理交互。
这意味着在建立连接期间,客户端必须向服务器提供有效的凭据。服务器可能支持不同类型的凭据,包括常规的用户名/密码、SASL、X.509密码或任何支持的机制。
除了安全性外,连接建立阶段还负责协商AMPQ协议的某些方面。在这一点上,如果客户端和/或服务器不能就协议版本或调整参数值达成一致,连接将不会被建立,传输层连接将被关闭。
3.1. 在Java应用程序中创建连接
当使用Java时,与RabbitMQ代理通信的标准方式是使用_amqp-client_ Java库。我们可以通过添加相应的Maven依赖项将此库添加到我们的项目中:
`<dependency>`
`<groupId>`com.rabbitmq`</groupId>`
`<artifactId>`amqp-client`</artifactId>`
`<version>`5.16.0`</version>`
`</dependency>`
此工件的最新版本可在Maven Central上获得。
这个库使用工厂模式来创建新连接。首先,我们创建一个新的_ConnectionFactory_实例,并设置创建连接所需的所有参数。至少,这需要通知RabbitMQ主机的地址:
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("amqp.example.com");
设置完这些参数后,我们使用_factory_的_newConnection()_工厂方法来创建一个新的_Connection_实例:
Connection conn = factory.newConnection();
4. 通道
**简单来说,AMQP通道是一种机制,允许在单个连接上复用多个逻辑流。**这允许在客户端和服务器端更好地使用资源,因为建立连接是一个相对昂贵的操作。
客户端创建一个或多个通道,以便它可以向代理发送命令。这包括与发送和/或接收消息相关的命令。
通道还提供了一些关于协议逻辑的额外保证:
- 对于给定通道的命令总是按照发送的相同顺序执行。
- 假设客户端在单个连接上打开多个通道,实现可以在它们之间分配可用的带宽。
- 双方都可以发出流量控制命令,告知对方应该停止发送消息。
通道的一个关键方面是其生命周期绑定到用于创建它的连接。这意味着如果我们关闭一个连接,所有相关联的通道也将被关闭。
4.1. 在Java应用程序中创建通道
使用_amqp-client_库的Java应用程序使用前者的_createChannel()方法从现有_Connection_创建一个新的_Channel:
channel = conn.createChannel();
一旦我们有了_Channel_,我们就可以向服务器发送命令。例如,要创建一个队列,我们使用_queueDeclare()_方法:
channel.queueDeclare("example.queue", true, false, true, null);
这段代码“声明”了一个队列,这是AMQP表示“如果尚不存在,则创建”的方式。队列名称后的附加参数定义了它的其他特性:
- durable: 此声明是持久的,意味着它将在服务器重启后存活
- exclusive: 此队列限制在与声明它的通道关联的连接上使用
- autodelete: 服务器将在不再使用时删除队列
- args: 用于调整队列行为的可选参数映射;例如,我们可以使用这些参数来定义消息的TTL和死信行为
现在,要使用默认交换机向此队列发布消息,我们使用_basicPublish()_方法:
channel.basicPublish("", queue, null, payload);
这段代码使用队列名称作为其路由键,将消息发送到默认交换机。
5. 通道分配策略
让我们考虑使用消息系统的场景:CQRS(命令查询责任分离)应用程序。简而言之,基于CQRS的应用程序有两个独立的路径:命令和查询。命令可以更改数据但从不返回值。另一方面,查询返回值但从不修改它们。
由于命令路径从不返回任何数据,服务可以异步执行它们。在典型的实现中,我们有一个HTTP POST端点,它在内部构建一个消息并将其发送到队列以供以后处理。
**现在,对于一个必须处理数十甚至数百个并发请求的服务来说,每次打开连接和通道都不是一个现实的选择。**相反,更好的方法是使用通道池。
当然,这引出了下一个问题:我们应该从单个连接创建通道,还是使用多个连接?
5.1. 单连接/多通道策略
在这个策略中,我们将使用单个连接,只创建一个通道池,其容量等于服务可以管理的最大并发连接数。对于传统的每个请求一个线程模型,这应该设置为与请求处理线程池的大小相同。
这种策略的缺点是,在较重的负载下,我们必须通过关联的通道逐个发送命令,这意味着我们必须使用同步机制。这反过来又增加了我们希望最小化的命令路径的额外延迟。
5.2. 每个线程连接策略
另一个选择是走向另一个极端,使用_Connection_池,这样就没有通道的竞争。对于每个_Connection_,我们将创建一个单个_Channel_,处理线程将使用它向服务器发出命令。
然而,我们从客户端移除同步的事实是有代价的。代理必须为每个连接分配额外的资源,如套接字描述符和状态信息。此外,服务器必须在客户端之间分割可用的吞吐量。
6. 基准测试策略
为了评估这些候选策略,让我们为每一个运行一个简单的基准测试。**基准测试包括并行运行多个工作器,每个发送一千条4 Kbytes的消息。**在构造时,工作器接收一个_Connection_,它将从中创建一个_Channel_来发送命令。它还接收迭代次数、有效载荷大小和一个_CountDownLatch_,用于通知测试运行器它已完成发送消息:
public class Worker implements Callable`<Worker.WorkerResult>` {
// ... 省略字段和构造函数
@Override
public WorkerResult call() throws Exception {
try {
long start = System.currentTimeMillis();
for (int i = 0; i `< iterations; i++) {
channel.basicPublish("", queue, null, payload);
}
long elapsed = System.currentTimeMillis() - start;
channel.queueDelete(queue);
return new WorkerResult(elapsed);
} finally {
counter.countDown();
}
}
public static class WorkerResult {
public final long elapsed;
WorkerResult(long elapsed) {
this.elapsed = elapsed;
}
}
}
除了通过减少锁存器来指示它已完成工作外,工作器还返回一个_WorkerResult_实例,其中包含发送所有消息所需的经过时间。虽然这里我们只有一个_long_值,我们可以扩展它以返回更多细节。
控制器根据正在评估的策略创建连接工厂和工作器。对于单连接,它创建_Connection_实例并将其传递给每个工作器:
@Override
public Long call() {
try {
Connection connection = factory.newConnection();
CountDownLatch counter = new CountDownLatch(workerCount);
List<Worker>` workers = new ArrayList<>();
for (int i = 0; i `< workerCount; i++) {
workers.add(new Worker("queue_" + i, connection, iterations, counter, payloadSize));
}
ExecutorService executor = new ThreadPoolExecutor(workerCount, workerCount, 0,
TimeUnit.SECONDS, new ArrayBlockingQueue<>`(workerCount, true));
long start = System.currentTimeMillis();
executor.invokeAll(workers);
if (counter.await(5, TimeUnit.MINUTES)) {
long elapsed = System.currentTimeMillis() - start;
return throughput(workerCount, iterations, elapsed);
} else {
throw new RuntimeException("Timeout waiting workers to complete");
}
} catch (Exception ex) {
throw new RuntimeException(ex);
}
}
对于多连接策略,我们为每个工作器创建一个新的_Connection_:
for (int i = 0; i < workerCount; i++) {
Connection conn = factory.newConnection();
workers.add(new Worker("queue_" + i, conn, iterations, counter, payloadSize));
}
_throughput_函数计算基准测量将是完成所有工作器所需的总时间除以工作器的数量:
private static long throughput(int workerCount, int iterations, long elapsed) {
return (iterations * workerCount * 1000) / elapsed;
}
注意我们需要将分子乘以1000,这样我们就可以得到每秒的消息吞吐量。
7. 运行基准测试
这些是我们对两种策略进行基准测试的结果。对于每个工作器计数,我们运行了10次基准测试,并使用平均值作为特定工作器/策略的吞吐量度量。环境本身按今天的标准来看是适度的:
- CPU: 双核心 i7 戴尔笔记本电脑 @ 3.0 GHz
- 总内存:16 GB
- RabbitMQ: 3.10.7 在 Docker 上运行(docker-machine 有 4 GB 内存)
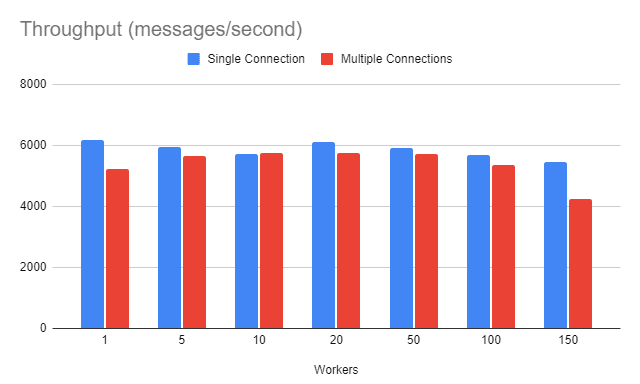
对于这个特定的环境,我们发现单连接策略有轻微的优势。这种优势在150个工作器的场景中似有所增加。
8. 选择策略
鉴于基准测试结果,我们不能指出一个明显的赢家。对于5到100个工作器的计数,结果或多或少是相同的。之后,与在单个连接上处理多个通道相比,多个连接的开销似乎更高。
我们还必须考虑测试工作器只做一件事:向队列发送固定消息。像我们提到的CQRS这样的现实世界应用程序,通常在发送消息之前和/或之后会做一些额外的工作。因此,为了选择最佳策略,推荐的方式是使用尽可能接近生产环境的配置运行您自己的基准测试。
9. 结论
在本文中,我们探讨了RabbitMQ中的通道和连接概念以及如何以不同方式使用它们。像往常一样,完整的代码可以在GitHub上找到。
![]()
![]()



OK