流媒体平台中消息传递语义
流媒体平台中消息传递语义
在本教程中,我们将讨论流媒体平台中的消息传递语义。
首先,我们将快速查看事件流通过流媒体平台的主要组件。接下来,我们将讨论这些平台中数据丢失和重复的常见原因。然后,我们将专注于可用的三种主要传递语义。
我们将讨论如何在流媒体平台中实现这些语义,以及它们如何处理数据丢失和重复问题。
在每种传递语义中,我们将简要触及在Apache Kafka中获得传递保证的方法。
2. 流媒体平台的基础知识
简单来说,像Apache Kafka和Apache ActiveMQ这样的流媒体平台以实时或近实时的方式处理来自一个或多个来源(也称为生产者)的事件,并将它们传递给一个或多个目的地(也称为消费者)进行进一步处理、转换、分析或存储。
生产者和消费者通过代理解耦,这使得可扩展性成为可能。
流媒体应用的一些用例可能是在电子商务网站上跟踪大量用户活动、实时金融交易和欺诈检测、需要实时处理的自主移动设备等。
消息传递平台有两个重要考虑因素:
- 准确性
- 延迟
通常,在分布式、实时系统中,我们需要根据系统更重要的因素,在延迟和准确性之间进行权衡。
这就是我们需要理解流媒体平台提供的开箱即用的传递保证的地方,或者使用消息元数据和平台配置实现所需的保证。
接下来,让我们简要看一下流媒体平台中的数据丢失和重复问题,然后讨论传递语义以管理这些问题,以满足个别系统需求。
3. 可能的数据丢失和重复场景
为了理解流媒体平台中的数据丢失和/或重复,让我们快速回顾一下流媒体平台中事件的高级流程:
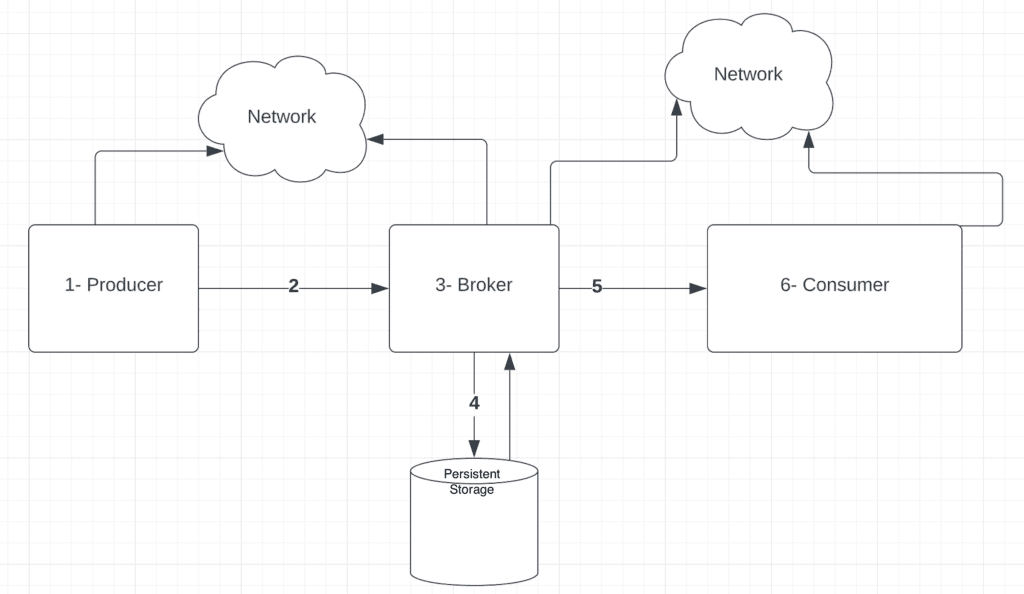
在这里,我们可以看到从生产者到消费者的流程中可能存在多个故障点。
通常情况下,这会导致数据丢失、延迟和消息重复等问题。
让我们专注于上图中每个组件,并看看可能出错的地方及其对流媒体系统可能产生的后果。
3.1. 生产者故障
生产者故障可能导致一些问题:
- 生产者生成消息后,在将其发送到网络之前可能会失败。这可能导致数据丢失。
- 生产者可能在等待从代理接收确认时失败。当生产者恢复时,它会尝试重新发送消息,假设没有收到来自代理的确认。这可能导致代理处的数据重复。
3.2. 生产者和代理之间的网络问题
生产者和代理之间可能存在网络故障:
- 生产者可能发送了一条消息,但由于网络问题,这条消息从未到达代理。
- 也可能存在这样一种情况:代理接收到消息并发送了确认,但由于网络问题,生产者从未收到确认。
在这两种情况下,生产者将重新发送消息,导致代理处的数据重复。
3.3. 代理故障
同样,代理故障也可能导致数据重复:
- 代理可能在将消息提交到持久存储并发送确认给生产者之前失败。这可能导致生产者重新发送数据,从而导致数据重复。
- 代理可能正在跟踪消费者迄今为止阅读的消息。代理可能在提交此信息之前失败。这可能导致消费者多次读取相同的消息,导致数据重复。
3.4. 消息持久性问题
从内存状态写入磁盘时可能会发生故障,导致数据丢失。
3.5. 消费者和代理之间的网络问题
代理和消费者之间可能存在网络故障:
- 尽管代理发送了消息并记录了发送消息的事实,但消费者可能从未收到消息。
- 类似地,消费者在接收消息后发送确认,但确认可能从未到达代理。
在这两种情况下,代理可能会重新发送消息,导致数据重复。
3.6. 消费者故障
- 消费者可能在处理消息之前失败。
- 消费者可能在将消息处理记录到持久性存储之前失败。
- 消费者也可能在记录已处理消息但在发送确认之前失败。
这可能导致消费者再次从代理请求相同的消息,导致数据重复。
接下来,让我们看看流媒体平台中可用的传递语义,以解决这些问题,以满足个别系统需求。
传递语义定义了流媒体平台如何保证在我们的流媒体应用中从源到目的地的事件传递。
有三种不同的传递语义可用:
- 至多一次(at-most-once)
- 至少一次(at-least-once)
- 精确一次(exactly-once)
4.1. 至多一次传递
在这种方法中,消费者首先保存最后接收到的事件的位置,然后处理它。
简单来说,如果事件处理在中间失败,在消费者重启后,它不能回退去读取旧的事件。
因此,不能保证所有接收到的事件都成功处理。
至多语义适用于某些数据丢失不是问题且准确性不是必须的情况。
以Apache Kafka为例,它使用偏移量来表示消息,至多一次保证的顺序将是:
- 持久化偏移量
- 持久化结果
为了在Kafka中启用至多一次语义,我们需要在消费者端设置“enable.auto.commit”为“true”。
如果发生故障并且消费者重启,它将查看最后持久化的偏移量。由于偏移量在实际事件处理之前就已经持久化了,我们无法确定消费者接收到的每个事件是否都已成功处理。在这种情况下,消费者可能会错过一些事件。
让我们可视化这种语义: 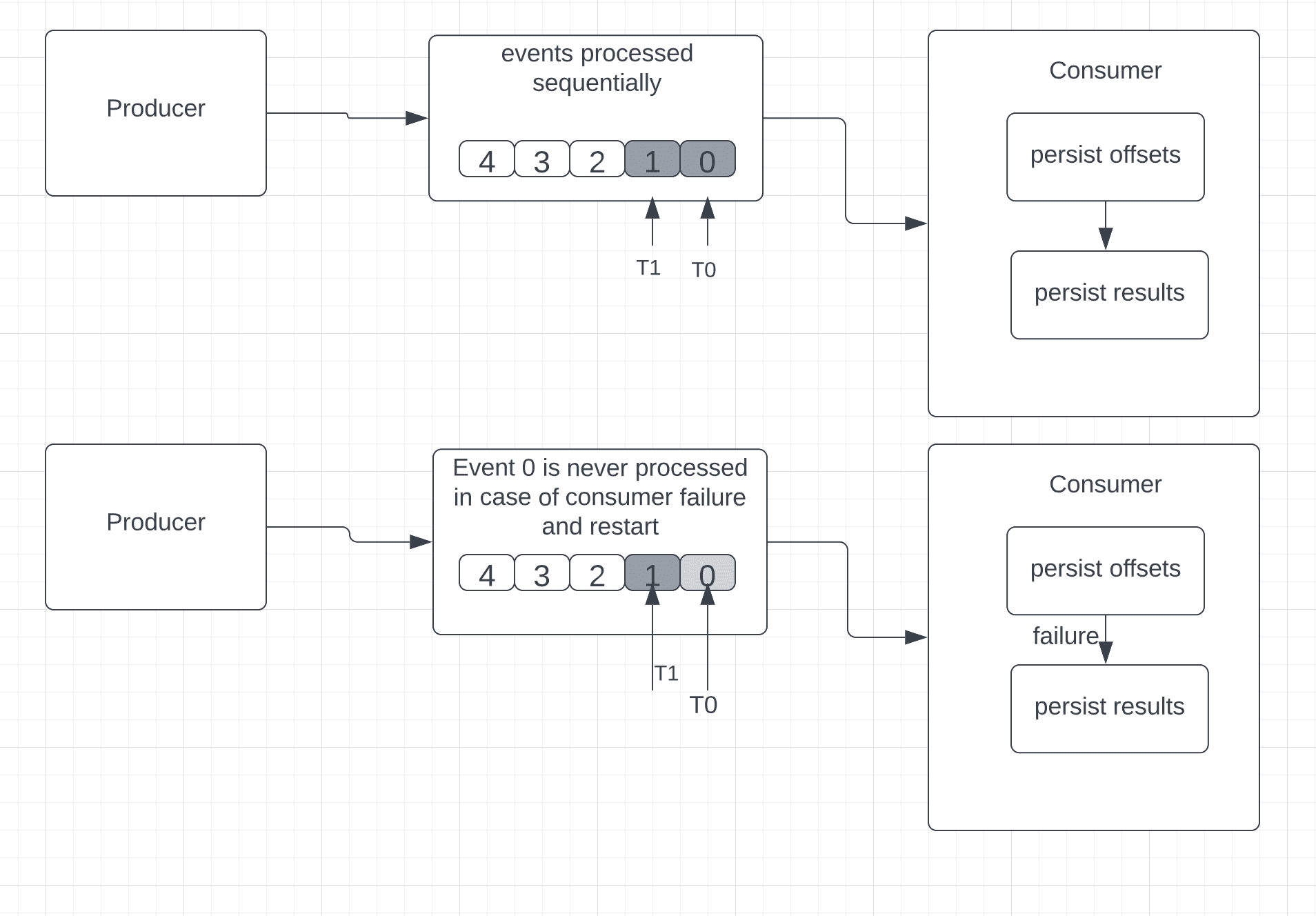
4.2. 至少一次传递
在这种方法中,消费者处理接收到的事件,在某处持久化结果,然后最后保存最后接收到的事件的位置。
与至多一次不同,在这里,如果发生故障,消费者可以读取并重新处理旧的事件。
在某些场景中,这可能导致数据重复。让我们考虑一个例子,消费者在处理并保存事件后但在保存最后已知事件位置(也称为偏移量)之前失败。
消费者将重启并从偏移量开始读取。在这里,消费者会多次重新处理事件,因为即使消息在故障之前已成功处理,最后接收到的事件的位置也没有成功保存:
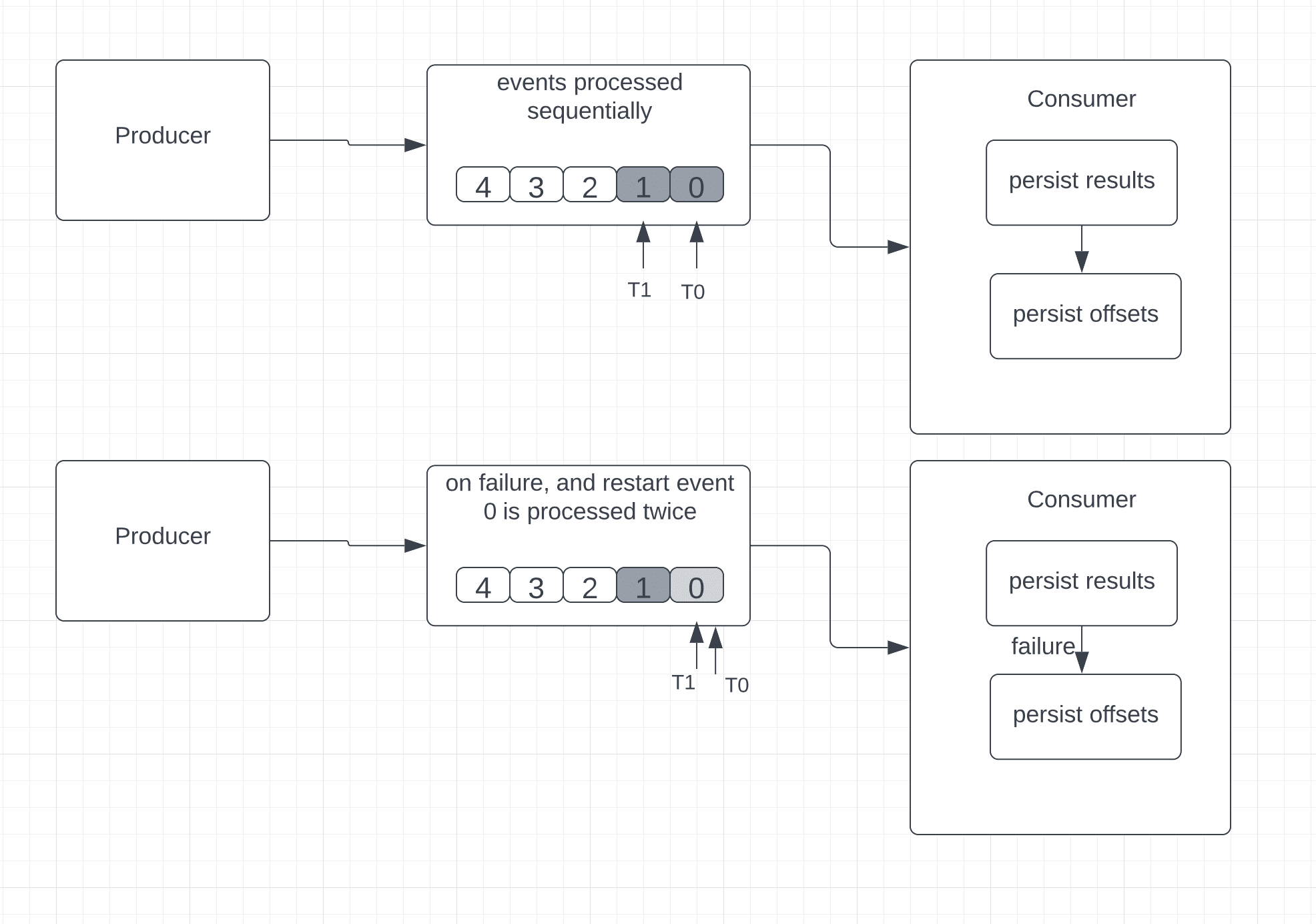
这种方法适用于任何更新计数器或仪表以显示当前值的应用程序。然而,需要准确性的聚合用例,如总和和计数器,对于至少一次处理并不理想,主要是因为重复事件会导致不正确的结果。
因此,在这种传递语义中,没有数据丢失,但可能会有情况,同一事件被重新处理。
为了避免多次处理同一事件,我们可以使用幂等消费者。
本质上,幂等消费者可以多次消费消息,但只处理一次。
以下方法的组合可以在至少一次传递中启用幂等消费者:
- 生产者为每条消息分配一个唯一的_messageId_。
- 消费者在数据库中维护所有已处理消息的记录。
- 当新消息到达时,消费者将其与持久化存储表中的现有_messageId_s_进行核对。
- 如果有匹配,消费者更新偏移量而不重新消费,发送确认,并有效地将消息标记为已消费。
- 当事件尚未存在时,启动数据库事务,并插入新的_messageId_。接下来,根据需要的任何业务逻辑处理这条新消息。消息处理完成后,事务最终提交。
在Kafka中,为确保至少一次语义,生产者必须等待来自代理的确认。
如果生产者没有收到代理的任何确认,它会重新发送消息。
此外,由于生产者以批次的形式将消息写入代理,如果那次写入失败并且生产者重试,批次中的消息可能会在Kafka中被写入多次。
然而,为了避免重复,Kafka引入了幂等生产者的功能。
本质上,为了在Kafka中启用至少一次语义,我们需要:
- 在生产者端设置属性“ack”的值为“1”
- 在消费者端设置“enable.auto.commit”属性的值为“false”。
- 设置“enable.idempotence”属性的值为“true”
- 从生产者附加每条消息的序列号和生产者ID
Kafka代理可以使用序列号和生产者ID在主题上识别消息重复。
4.3. 精确一次传递
这种传递保证与至少一次语义类似。首先,接收到的事件被处理,然后结果被存储在某个地方。如果发生故障并重启,消费者可以重新读取和处理旧的事件。然而,与至少一次处理不同,任何重复的事件都被丢弃并不再处理,从而实现精确一次处理。
这对于准确性很重要的任何应用程序都是理想的,例如涉及聚合的应用程序,如准确的计数器或任何需要事件只处理一次且不丢失的应用程序。
序列继续翻译:
如下:
- 进行如下操作:
- 持久化结果
- 持久化偏移量
让我们看看当消费者在处理事件后但在保存偏移量之前失败会发生什么:
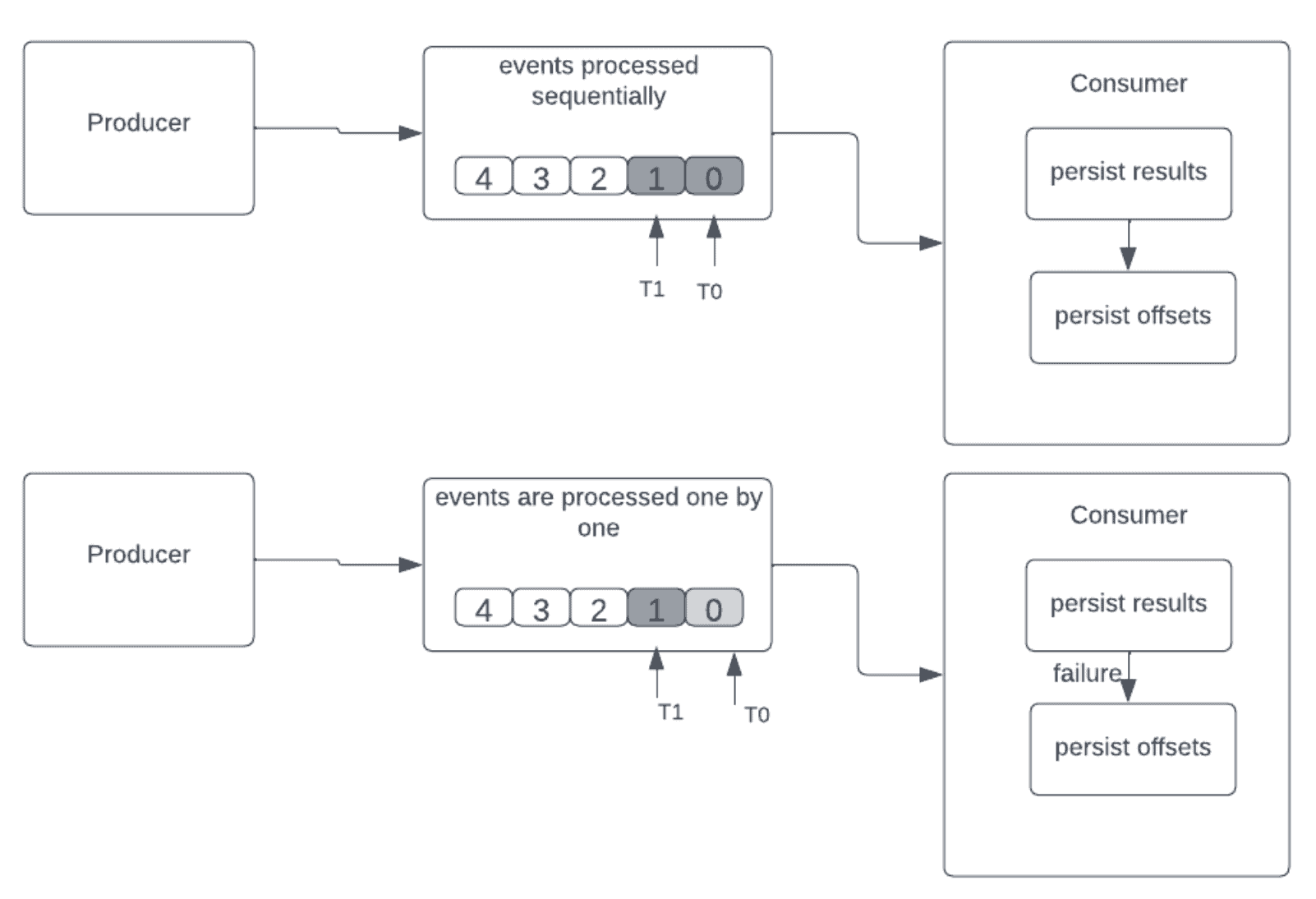
我们可以通过以下方式在精确一次语义中消除重复:
- 幂等更新 - 我们将结果保存在生成的唯一键或ID上。在发生重复的情况下,生成的键或ID已经在结果中(例如数据库),因此消费者可以删除重复项而不需要更新结果。
- 事务性更新 - 我们将结果以批次的形式保存,需要开始和提交事务,因此在提交事件时,事件将被成功处理。在这里,我们将简单地丢弃重复事件而不更新任何结果。
让我们看看在Kafka中启用精确一次语义需要做什么:
- 通过为每个生产者设置唯一的“transaction.id”值来启用幂等生产者和事务功能
- 通过将属性“isolation.level”设置为“read_committed”来启用消费者的事务功能
5. 结论
在本文中,我们看到了流媒体平台中使用的三种传递语义之间的区别。
在简要概述了流媒体平台中的事件流程之后,我们查看了数据丢失和重复问题。然后,我们看到了如何使用各种传递语义来缓解这些问题。我们接着看了至少一次传递,然后是至多一次,最后是精确一次传递语义。
![]()

OK